MoE; Mixtral of Experts
2024.01
Motivation
Mixture of Experts
Mixture of Experts는 무엇인가?
입력에 따라 전체 모델을 쓰지 않고 일부 전문가만 선택적으로 활성화하는 앙상블 학습 기법
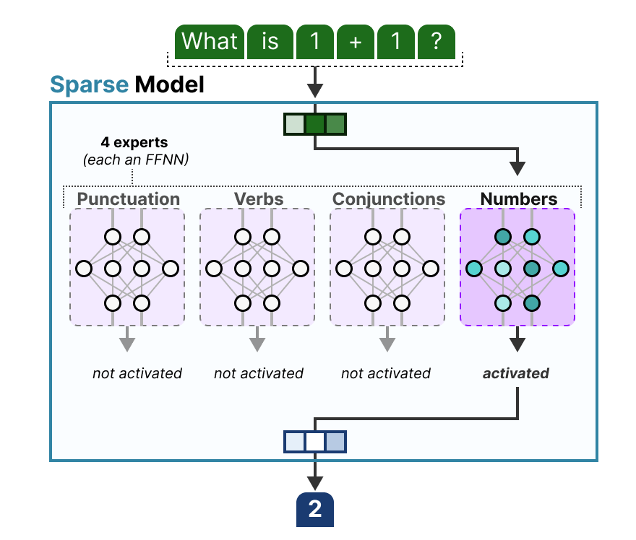 (출처: https://newsletter.maartengrootendorst.com/p/a-visual-guide-to-mixture-of-experts)
(출처: https://newsletter.maartengrootendorst.com/p/a-visual-guide-to-mixture-of-experts)
입력이 들어오면 -> 게이트가 어떤 Expert를 쓸지 결정하고 [Routing] -> 선택된 Expert만 활성화 -> 활성화된 Expert의 출력을 weighted sum/또는 mean값 처리 후(합산) 최종 결과를 출력한다.
직관적으로는 계산을 줄이기 때문에 효율성, 확장성이 높아 보인다.
구성요소
- Gate 어떤 전문가를 사용할지 결정하는 역할. 입력 벡터를 보고 각 Expert에 대한 “활성화 점수”를 계산한다.
- Experts 일반적으로 Feedforward Network처럼 생긴 여러 개의 하위 네트워크
- Sparse Routing 모든 Expert를 쓰지 않고, 입력당 상위 N개의 Expert만 활성화시켜서 계산(보통 N=2)
Mixture of Experts는 어떤 필요에 의해 등장했는가?
“Efficiency of Inference”
- 더 큰 모델 = 더 좋은 성능?
- but 계산비용과 메모리도 동시에 폭발적으로 증가하기 때문에 자원의 한계
- 모든 입력에 대해 전체 네트워크를 돌리면 실시간 사용이 어렵고, 비효율적이다.
그래서 Dense(전체 활성화) 네트워크 대신, Sparse Activation이 해결책으로 등장함. 그중 하나가 MoE
MoE는 어떤 변화를 가져왔는가?
MoE 이전의 LLM 패러다임은, 하나의 거대한 모델(신경망)을 만드는게 목표였다. 그래서 성능을 키우기 위해 점점 더 거대한 dense모델(ex. GPT-3)을 만들었다.
MoE는 입력 맞춤형 계산으로, 단순히 파라미터 수를 키우던 이전과 달리 높은 효율의 계산을 가능하게 해서 성능과 비용의 tradeoff를 해소했다.
추론 시에 입력 맞춤형으로 일부 전문가만 활성화하는 것처럼, 학습할 때도 일부 전문가만 활성화된다. 따라서 각 전문가가 전체 데이터가 아니라 일부 입력에만 노출돼서 학습된다.
추가) 학습은 오히려 더 어렵고 비용이 크다고 한다.
- 전문가마다 다른 부분을 업데이트해야 되니까 parameter sparsity에 따른 gradient sparsity 문제 발생
- 일부 expert에만 편향 생기는 현상: load balancing 문제
- auxiliary loss 추가 계산 비용
- 일반 dense 모델에 비해 통신비용, 분산 처리 복잡도: computational bottleneck
학습이 진행될수록 Gate는 각 입력에 더 잘 맞는 전문가를 더 자주 선택하게 되고, 자주 선택된 전문가들은 특정 입력에 맞게 파인튜닝되는 것이다.
이때 유의해야 할 점은, 모든 전문가가 고르게 선택되지 않으면 일부 전문가만 과도하게 학습된다는 점이다. 게이팅 네트워크는 대부분 소수의 expert만을 활성화하는 방향으로 수렴하는 경향이 있다. 그래서 일반적으로 MoE 논문들에서는 Load Balancing loss로 auxiliary loss을 추가해서, 게이트가 모든 전문가를 적절히 고르게 사용하도록, 그래서 각 expert가 대략 동일한 수의 학습 예제를 받을 수 있도록 유도한다. expert capacity 역시 해결책 중 하나로, 하나의 expert가 처리할 수 있는 토큰 수에 제한을 두는 것이다.
그러면 또 드는 의문이.. 전문가들이 고르게 사용되도록 뽑으면 ‘특화’가 아니라 그냥 다같이 모자란 Generalist가 될 수도 있다.
➡️ Routing Analysis에서 조금 이해가 된 것 같기도..?
균형을 맞추는 것이 가장 큰 문제기 때문에 loss의 weight을 조절해서 너무 강하게 쓰지 않고, soft하게 적용하고자 한다.
Mixtral of Experts
abstract + introduction
- Mixtral 8x7B: Sparse Mixtral of Experts(SMoE) 기반의 decoder-only 언어 모델 8개의 expert, 70억개의 파라미터를 의미한다.
- 8 x 7B = 56B
- 파라미터 총합은 expert 56B(560억 파라미터) + shared 1.3B(embedding, attention 등) 해서 총 57.3B
- 실제로 한 번에 사용하는 파라미터 수는 2x7B =14B + 1.3B = 15.3B 정도만 활성화
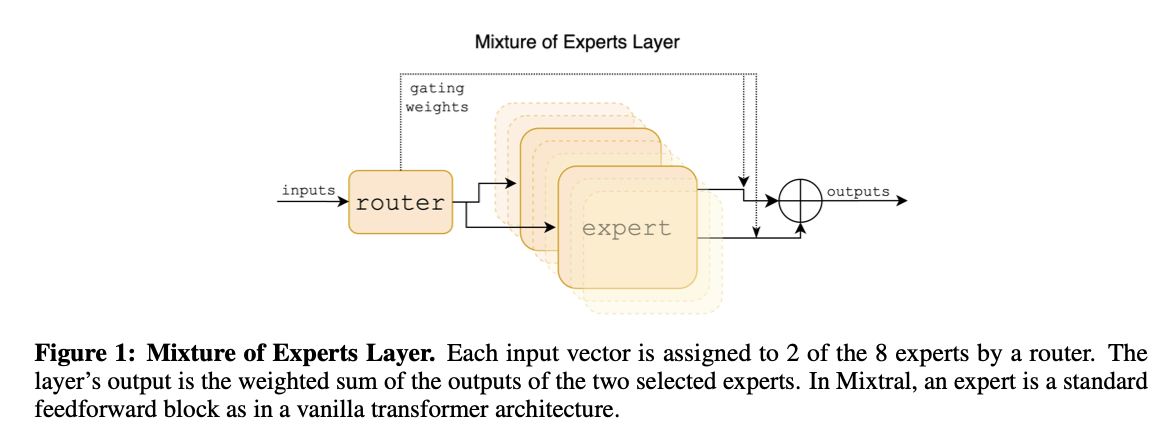
- Mistral 7B와 동일한 아키텍쳐를 기반으로 하지만, 각 레이어가 8개의 Feedforward block(=expert)로 구성된다는 점이 다르다.
- 모든 레이어에서 매 토큰마다 두 개의 expert를 선택하여 처리하고, 그 출력을 합산한다.
- 매 시점마다 다른 expert가 선택될 수 있기 때문에, 각 토큰은 총 470억개의 파라미터에 접근 가능하며, 추론 시에는 그 중 130억개의 파라미터만 실제로 사용된다.
- 모델의 전체 파라미터 수를 증가시키면서도, 토큰당 사용하는 파라미터 수는 제한하므로 cost & latency를 효율적으로 제어할 수 있게 해준다.
- 매 토큰마다 전체 파라미터 중 일부만 사용하기 때문에 소규모 배치에서는 더 빠른 추론 속도를, 대규모 배치에서는 높은 처리량을 가능하게 한다.
- 32k 토큰 길이의 context size를 사용해 다국어 데이터를 기반으로 pre-trained되었다.
- 모든 벤치마크에서 Llama2 70B와 GPT-3.5보다 뛰어난 성능을 보인다.
- 특히 수학, 코드 생성, 다국어 벤치마크에서 Llama2를 크게 앞섰다.
- Mixtral 8x7B - Instruct도 함께 소개한다.
- instruction-following을 목표로 지도학습과 DPO(Direct Preference Optimization)을 사용해 파인튜닝된 chat model이다.
- BBQ, BOLD등의 벤치마크에서 편향이 적고, 더 균형잡힌 sentiment profile(감성 분석)을 보여준다.
architectural details
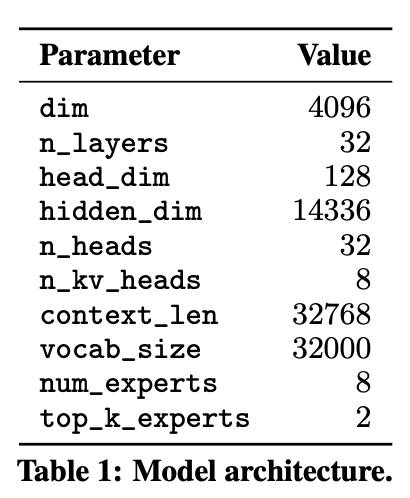 Transformer를 기반으로 하지만,
Transformer를 기반으로 하지만,
- 32k 토큰의 dense context size를 지원
- Feedforward block이 Mixture-of-Experts 레이어로 대체됨
Sparse Mixture of Experts
“Sparse”: Gating vector G(x)가 sparse(희소)하다면, 연산 효율 향상 대부분의 값이 0이면 해당하는 expert는 계산할 필요가 없기 때문이다.
- expert 집합: \({E_0, E_1, ..., E_{n-1}}\)
- Gating network 출력: \(G(x)_i\)
- 가중치로 작용한다.
- i번째 expert의 출력: E_i(x)
expert layer의 최종 출력: \(\sum^{n-1}_{i=0}G(x)_i \cdot E_i(x)\)
- 입력 x에 대해, 여러 expert 네트워크의 출력 중 일부만 선택해서 weighted sum 계산
Gating Network: \(G(x) := Softmax(TopK(x \cdot W_g))\)
- \(x \cdot W_g\): 인풋에 선형변환을 적용한 결과
- TopK: 상위 k개 값만 남기고, 나머지는 \(-\infin\)로 설정하여 softmax에서 0에 수렴하게 만든다.
- K: 하이퍼파라미터로, 한 토큰당 사용할 expert 수를 조절한다.
이렇게 하면 expert수 N을 늘려도, 사용할 expert 수 K는 고정할 수 있어서 총 파라미터 수(sparse parameter count)는 늘어나지만, 실제 연산량(active parameter count)은 일정하게 유지할 수 있다.
MoE를 더욱 효율적으로 만드는 기술
Megablocks: MoE의 피드포워드 네트워크 연산을 large sparse matrix multiplications로 cast하여 실행 속도 향상 MoE에서는 여러 expert 중 일부만 선택해서 FFN 연산을 수행하기 때문에, 토큰마다 선택되는 expert가 다르다 보니 병렬 처리하기가 어렵다. (지금 이 expert에 몇 개 토큰이 왔는지가 매번 다름) 이 문제를, Megablocks를 통해 하나의 커다란 sparse 행렬곱으로 바꿔버린다. 여기서 sparse는: 0이 많다는 뜻 이를 통해 여러 expert를 처리하는 로직이 깔끔하게 통합되어 안정적이고, GPU에 최적화된 sparse 행렬곱 커널을 활용할 수 있어서 속도가 훨씬 빨라진다.
Model Parallelism + Expert Parallelism (EP) Model Parallelism: Mixtral처럼 파라미터가 수십억개가 넘는 큰 모델은 절대 하나의 GPU로는 돌릴 수 없기 때문에, 여러 GPU에 나누어 분산 처리 Expert Parallelism: 한 레이어에 여러 개의 expert가 있는데, 이 expert들 역시 하나의 GPU에 다 올리기엔 너무 무겁다. 그래서 각 expert를 서로 다른 GPU에 하나씩 나눠서 저장하는 방식이다. (ex. GPU 0 -> Expert 0 ~ GPU 7 -> Expert 7)
router가 expert를 지정하면, 각 토큰은 해당하는 GPU로 보내지고, 처리된 결과는 다시 원래 토큰의 위치로 되돌아온다.
여기서 Load Balancing 문제가 발생할 수 있다. 토큰 수에 따라 어떤 GPU는 일이 많고 어떤 GPU는 놀고 있기 때문 또한, 토큰이 이동하면서 computational bottleneck 현상이 일어날 수 있다.
최종: input token x에 대한 output y Mixtral 에서는 expert function으로 SwiGLU구조(FFN)를 사용한다. \(y = \sum^{n-1}_{i=0}Softmax(Top2(x \cdot W_g))_i \cdot SwiGLU_i(x)\)
GShard와의 차이점
- Mixtral은 모든 FFN 서브블록을 MoE로 대체
- GShard는 두 번째 expert 선택 시 더 복잡한 게이팅 전략 사용
Mixtral의 Load Balancing Loss?
 논문에서는 언급이 없지만, Mixtral 깃허브의 transformers 코드를 확인해보면 Load Balancing Loss 함수가 있다. 이 함수를 통해 선택 빈도뿐 아니라, 게이트의 선택 확률 분포 자체에 패널티를 줘서 부드럽게 조정함을 알 수 있다.
논문에서는 언급이 없지만, Mixtral 깃허브의 transformers 코드를 확인해보면 Load Balancing Loss 함수가 있다. 이 함수를 통해 선택 빈도뿐 아니라, 게이트의 선택 확률 분포 자체에 패널티를 줘서 부드럽게 조정함을 알 수 있다.
❗️Routing Analysis
result 뒤에 있는 섹션이지만 궁금했던 내용이어서 얘를 먼저 다룬다. 이 섹션에서는 router가 expert를 어떻게 선택하는지에 대한 분석을 다룬다.
아래의 차트는 The Pile validation dataset에 대해 선택된 expert의 분포를 측정한 결과다. 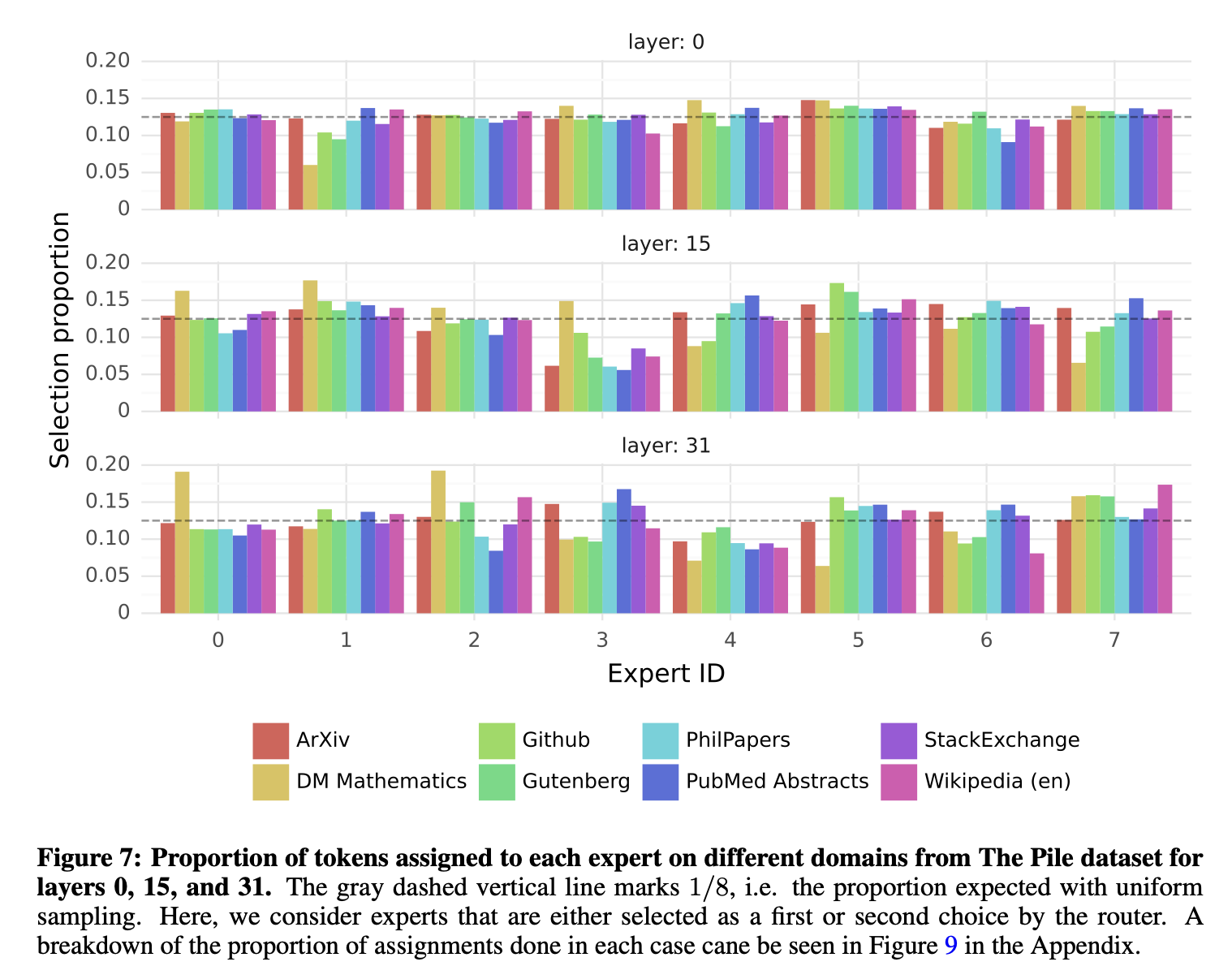 회색 선이 1/8, 즉 완전히 균등한 분포일 경우이다. 예상 외로, **<주제에 따라="" 할당되는="" expert="">의 뚜렷한 패턴은 관찰되지 않았다.**
회색 선이 1/8, 즉 완전히 균등한 분포일 경우이다. 예상 외로, **<주제에 따라="" 할당되는="" expert="">의 뚜렷한 패턴은 관찰되지 않았다.**
모든 레이어에서 다음 3가지 문서 유형에 대해 expert 할당 분포가 매우 유사했다.
- ArXiv 논문
- 생물학
- 철학 도메인과 전혀 상관없는 것이 보인다..
단, DM Mathematics 데이터셋의 경우에는 약간 다른 expert 분포가 나타났는데, 이는 이 데이터셋이 synthetic(합성: 인간이 만든)하고, 자연어 스펙트럼을 충분히 포괄하지 못한다는 특성에서 기인하는 것으로 보인다.
첫 번째로 선택된 expert에 따라 색칠된 텍스트 샘플들이다.  expert 도메인보다는 문법에 더 잘 맞춰지는 경향을 보이며, 이러한 현상은 특히 초기 레이어(입력 근처)와 마지막 레이어(출력 근처)에서 더 뚜렷하게 드러난다. 이 두 레이어는 각각 입력/출력 임베딩과 높은 상관관계를 가지는 특성을 가지고 있기 때문이다.
expert 도메인보다는 문법에 더 잘 맞춰지는 경향을 보이며, 이러한 현상은 특히 초기 레이어(입력 근처)와 마지막 레이어(출력 근처)에서 더 뚜렷하게 드러난다. 이 두 레이어는 각각 입력/출력 임베딩과 높은 상관관계를 가지는 특성을 가지고 있기 때문이다.
예를 들어
- Python 코드에서 ‘self’같은 단어
- 영어 문장에서 ‘Question’같은 단어 는 여러 토큰으로 구성되어 있음에도 자주 같은 expert를 통해 routing된다. (하나의 레이어 안에서) (MoE 구조에서는 각 레이어마다 독립적인 router, 즉 레이어별로 expert를 따로 결정하기 때문에 - 이 레이어에서는 어떤 expert로 routing되었는가 를 기준으로 분석한다. routing의 확률분포가 나중에 가중치로 작용하는 것!📊)
나는 expert가 균등하게 사용되면
- A도메인의 expert 1에게 가야할 A도메인의 학습 예제가
- expert 1이 이미 너무 많이 학습했다는 이유로 B도메인의 expert 2한테 가서 성능이 떨어지는 경우를 걱정했는데,
이렇게 도메인 지식 기준이 아니라 문법에 따라 특화되는거면 크게 문제가 되지 않나 싶기도 하다..
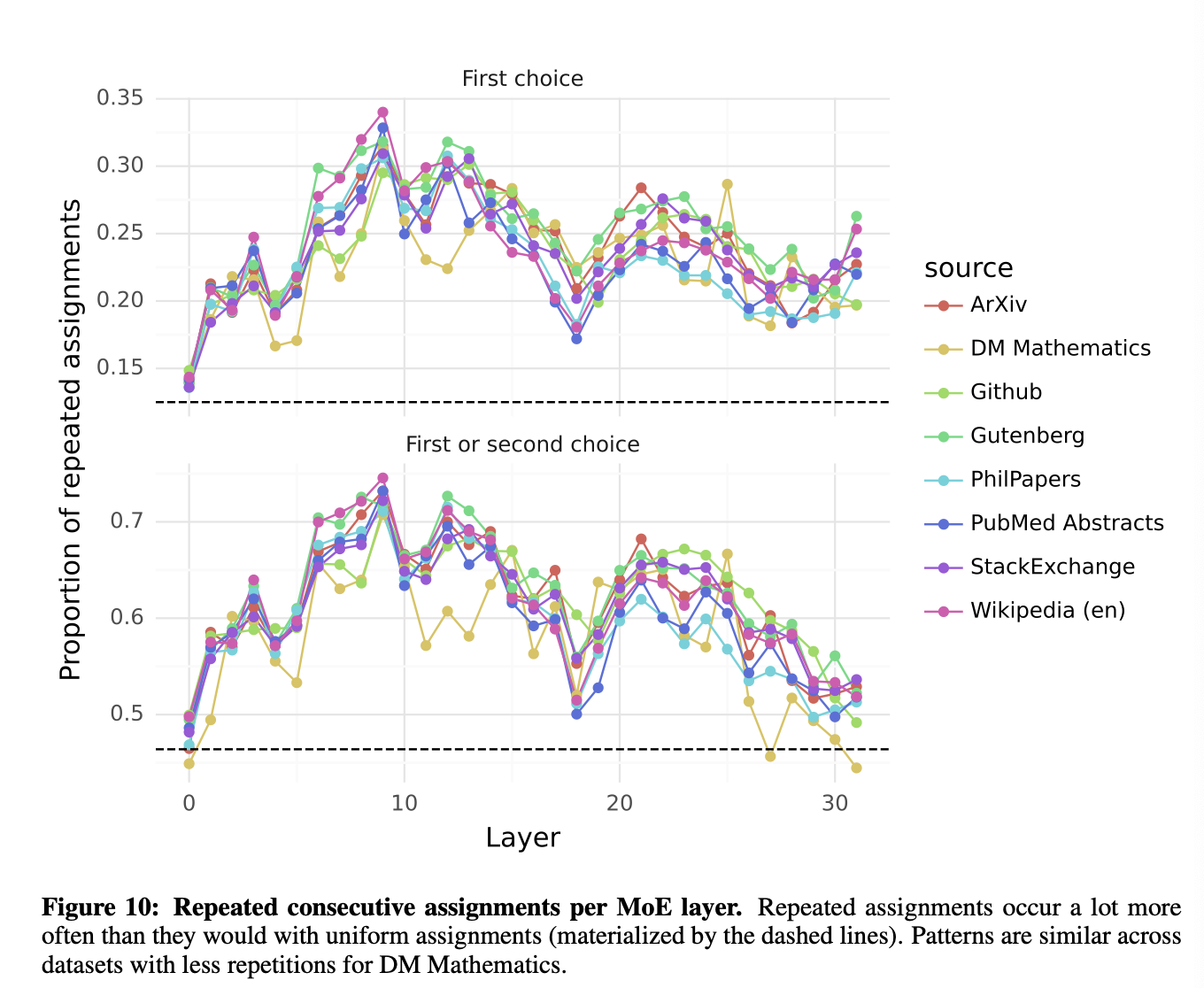
❗️Figure 8에서 확인할 수 있는 또다른 인사이트: 연속된 토큰들이 자주 같은 expert에 할당된다는 것, 즉 _positional locality_가 나타난다. 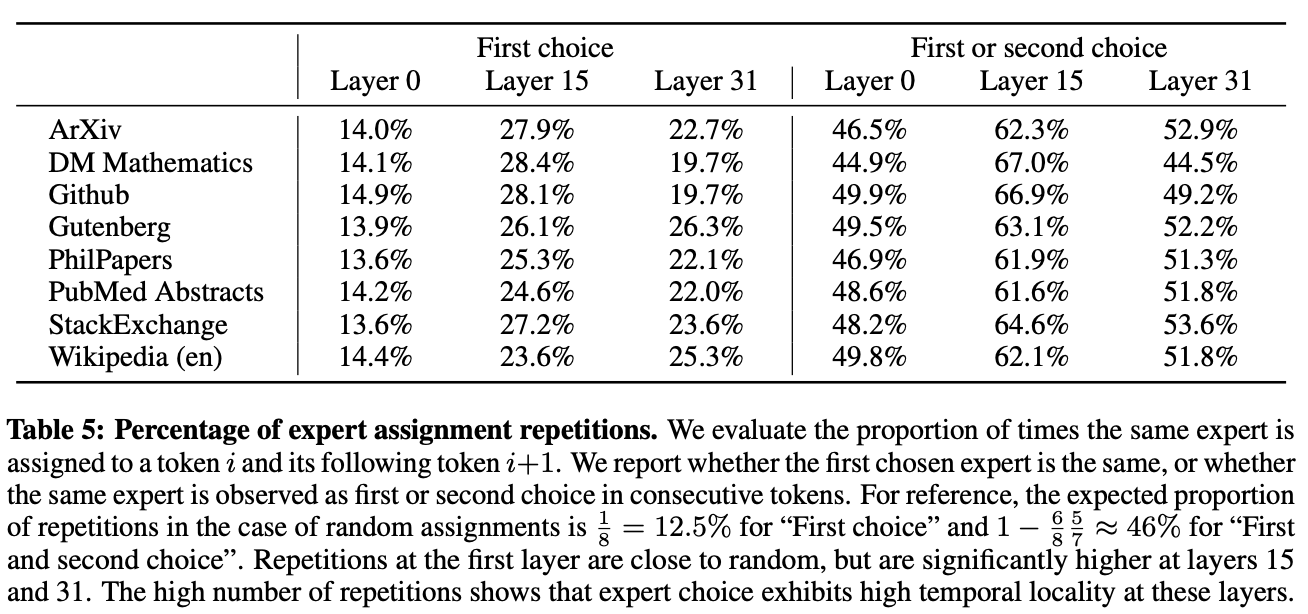
높은 locality가 있는 경우, expert parallelism을 적용할 때 일부 expert에 과부하가 걸릴 가능성이 높아진다.
result
다양한 벤치마크에 대해 llama와 비교한 결과 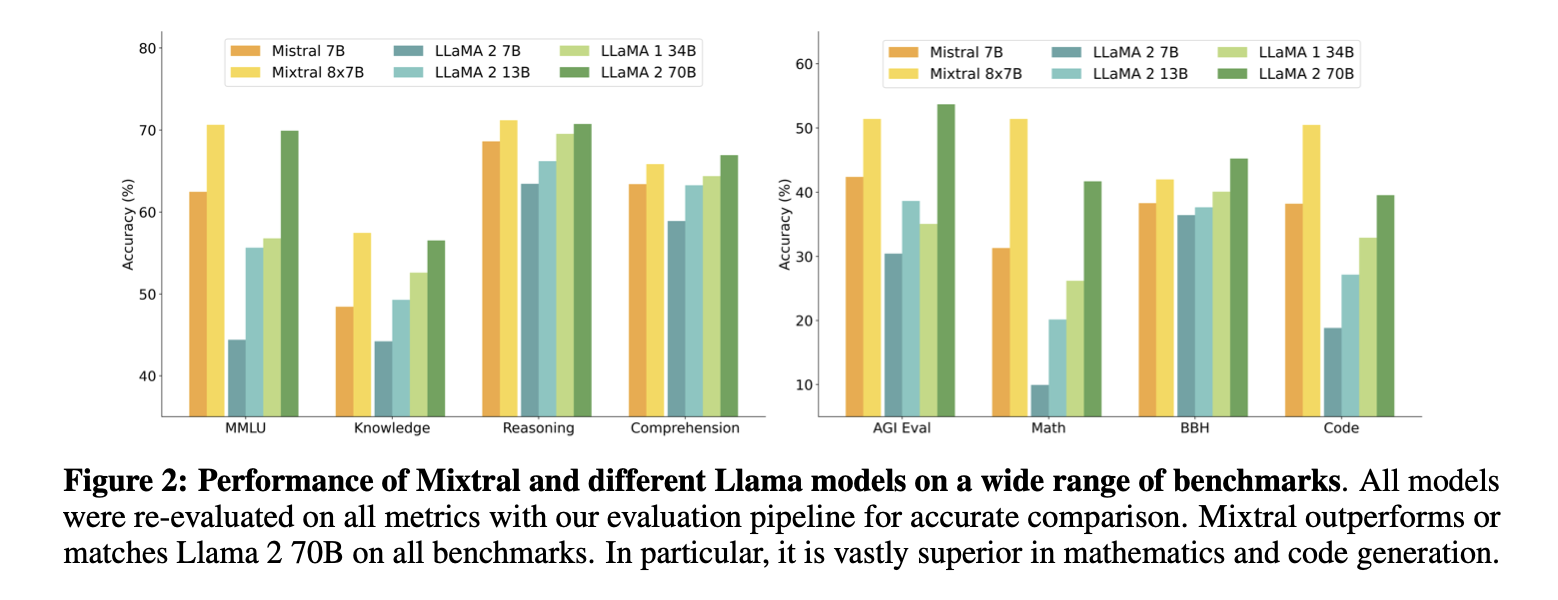
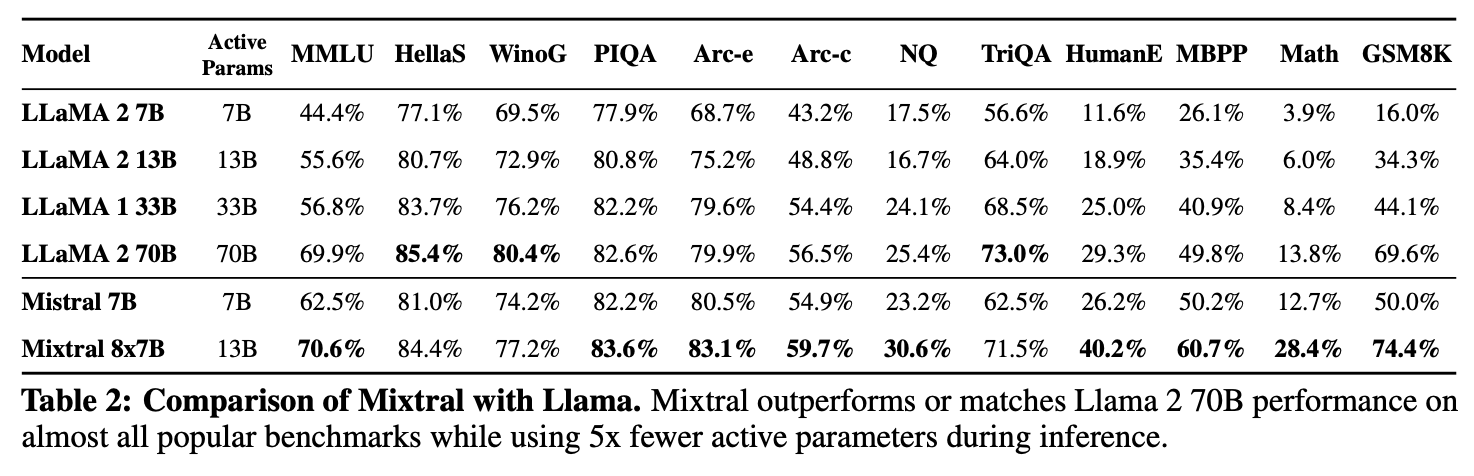 inference에서 5배 적은 active parameter를 썼으나 성능은 같거나 더 좋다
inference에서 5배 적은 active parameter를 썼으나 성능은 같거나 더 좋다
수학, 코드 벤치마크 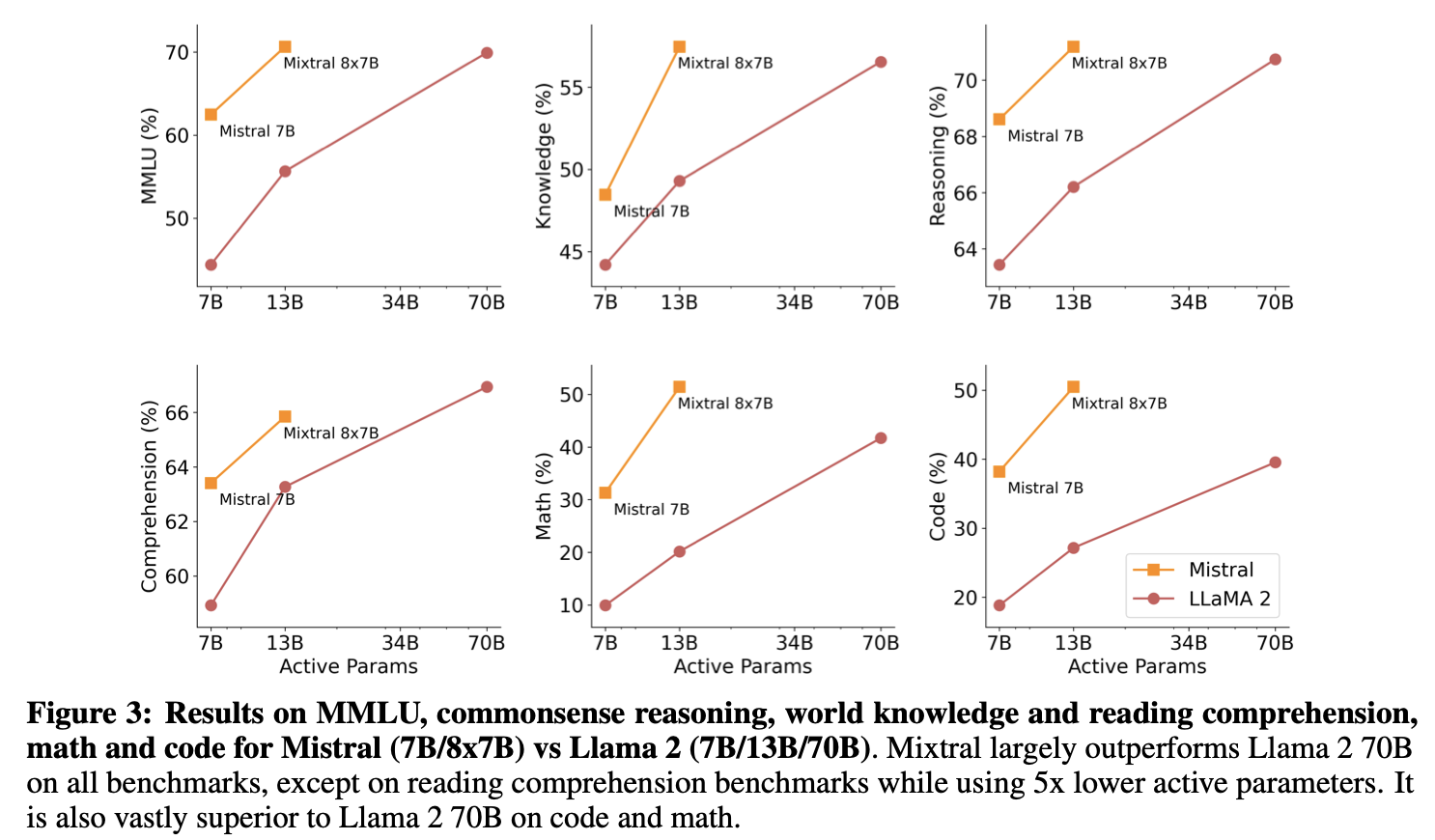
GPT-3.5까지 비교한 결과 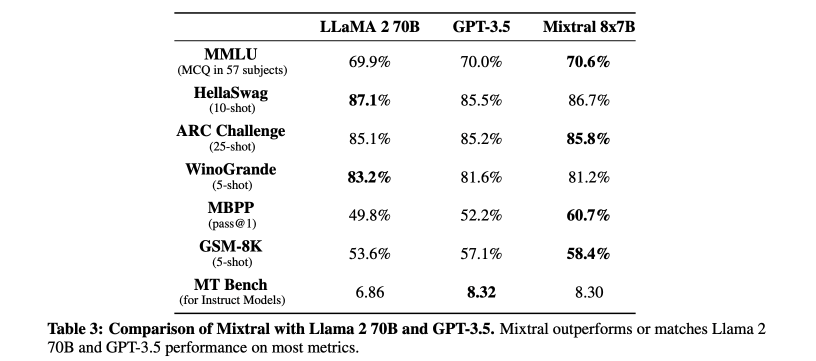
multilingual benchmarks 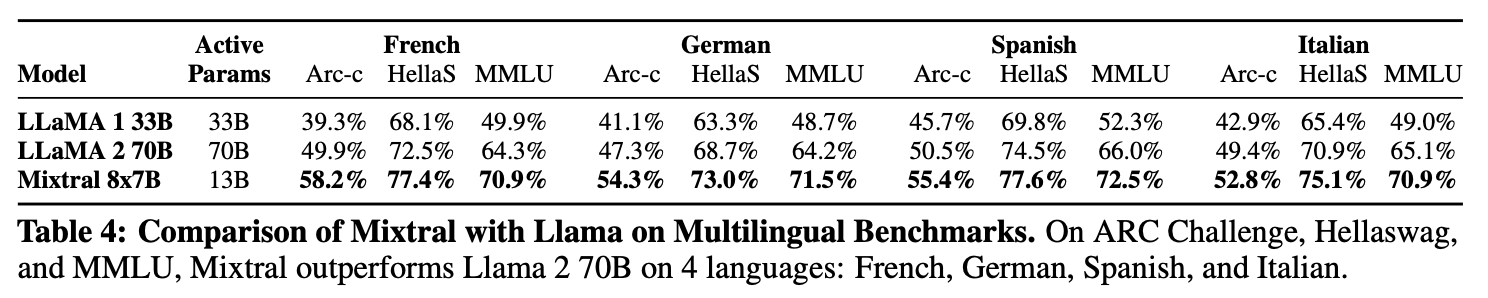
long range performance 긴 문맥 처리 능력 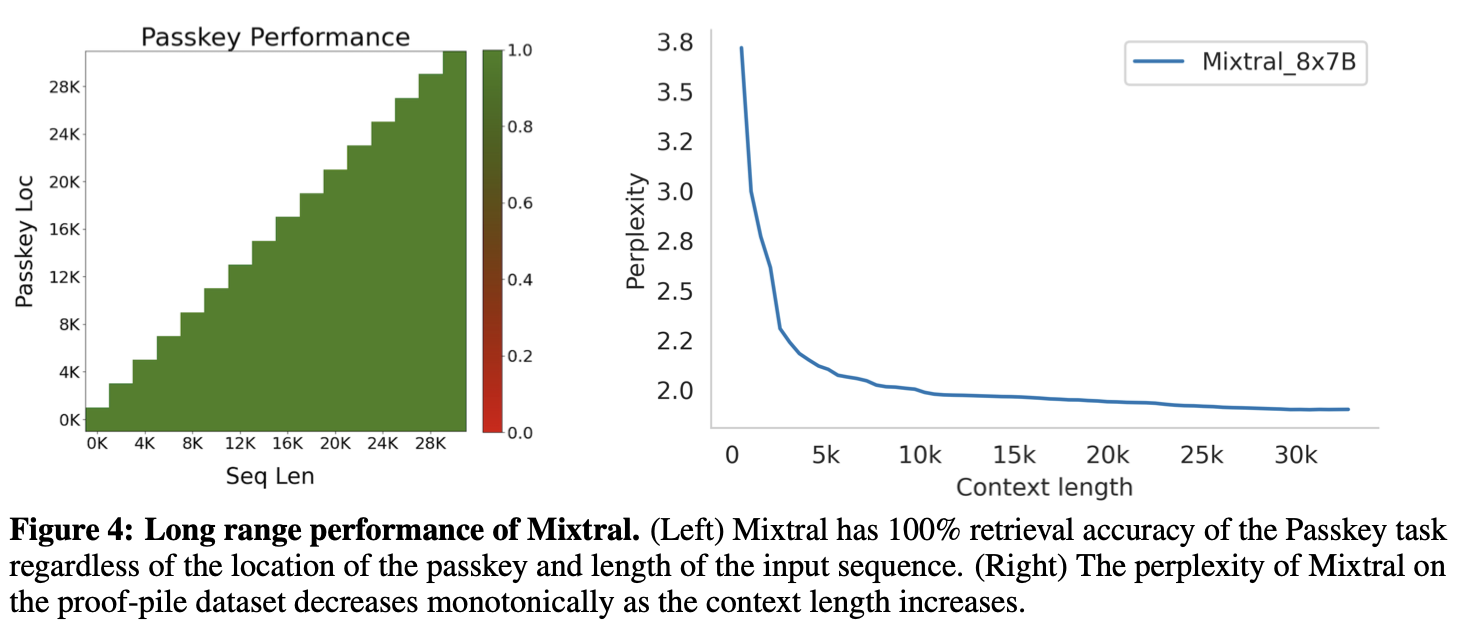 Mixtral은 32K 길이의 긴 문맥에서도 정보를 정확하게 검색해낼 수 있으며, 문맥이 길수록 언어 이해 능력이 더 향상되었다. 긴 문맥 처리를 잘 못하던 Transformer의 개선점을 알려준 실험이고, MoE의 기능과는 크게 관련 없는 듯 하다.
Mixtral은 32K 길이의 긴 문맥에서도 정보를 정확하게 검색해낼 수 있으며, 문맥이 길수록 언어 이해 능력이 더 향상되었다. 긴 문맥 처리를 잘 못하던 Transformer의 개선점을 알려준 실험이고, MoE의 기능과는 크게 관련 없는 듯 하다.
추가 내용 (ST-MoE)
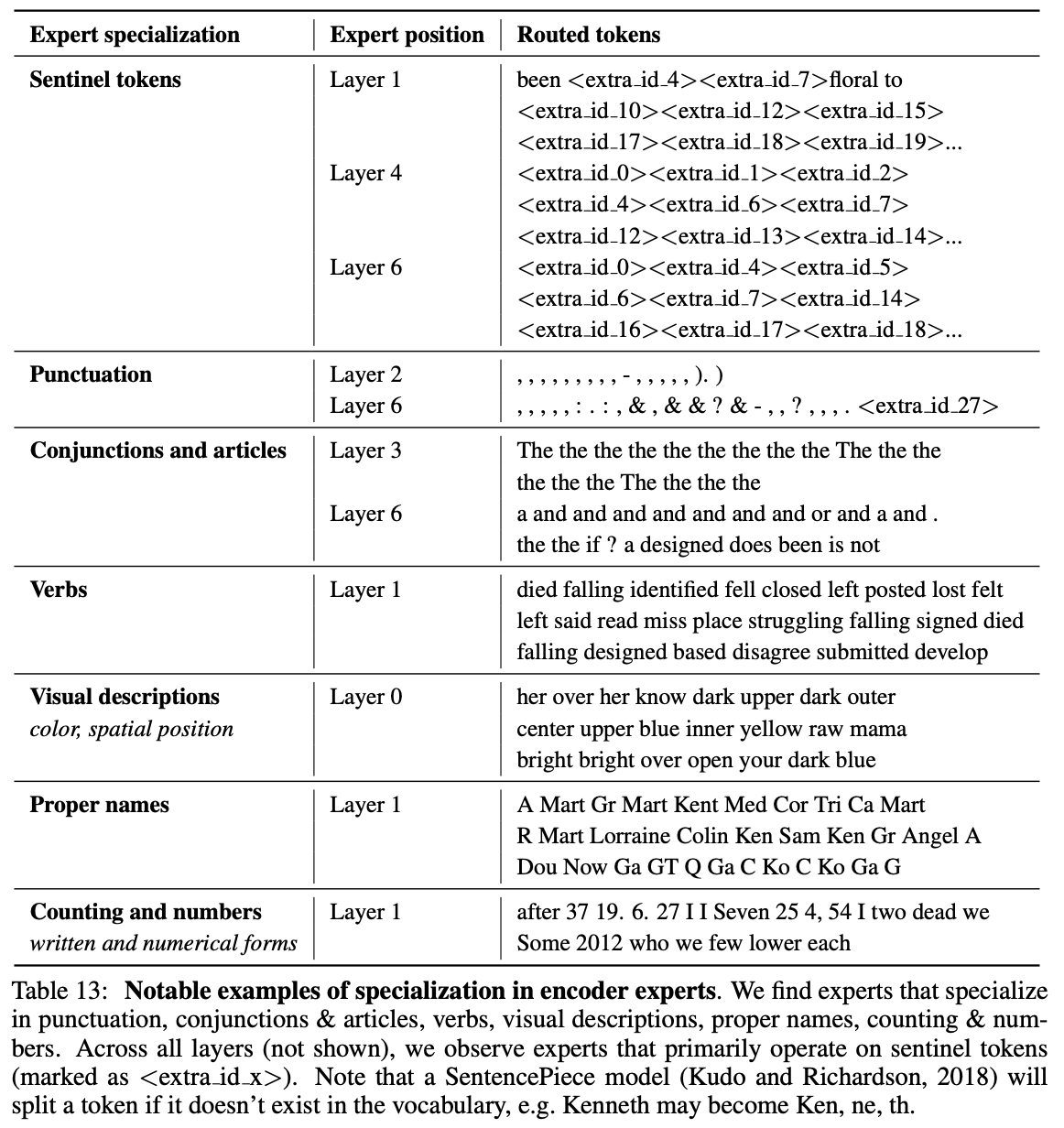
ST-MoE 논문의 실험에 의하면, 일부 인코더 experts는 특화된 전문성을 보였으나 디코더 experts는 전문성을 보이지 못했다.
- Encoder experts 주로 구두점, 동사, 고유 명사, 숫자 처리 등에 작동했다.
- Decoder experts 디코더 expert에서는 특수화가 거의 관찰되지 않았다고 한다. 두 가지 이유를 추론해볼 수 있다.
- Routing되는 토큰의 수가 적다 특정 토큰을 어느 expert에게 보낼지 결정하는 Routing 과정에서, 한 번에 여러 토큰을 묶어서 처리한다. 인코더는 한 그룹에 2048개의 토큰을 넣어서 expert에게 보내고, 디코더는 한 그룹에 456개의 토큰만 넣는다. 결과적으로, 디코더에서 각 expert가 보는 토큰 수 자체가 적기 때문에 인풋의 패턴을 잡고 특화되기가 어려워진다.
- 디코더에서 sentinel 토큰의 비율이 더 높다 sentinel 토큰은 빈칸 역할을 하는 토큰으로,
과 같이 빈칸의 시작을 알려주는 신호들로 이루어져 있다. 근데 이 토큰의 비율이 더 높으면 실제 내용보다는 비슷하게 생긴 sentinel 패턴들에만 익숙해지고, 의미 영역에 특화될 수 없는 상황이 벌어지는 것이다.
개선이 어떻게 진행되고 있는지 좀 더 찾아봐야 할 것 같다.
참고: https://huggingface.co/blog/moe?utm_source=chatgpt.com#load-balancing-tokens-for-moes
