Distilling Step-by-Step! Outperforming Larger Language Models with Less Training Data and Smaller Model Sizes
Distillation
지식 증류; 큰 모델(teacher model)이 가진 지식을 작은 모델(student model)로 전이하여 작은 모델이 성능을 향상하도록 돕는 머신러닝 기법
아이디어
- 큰 모델 훈련
- LLM 같은 강력한 모델을 먼저 훈련시킨다.
- 출력 소프트 라벨 생성
- Teacher Model이 특정 데이터에 대해 예측한 결과(soft label)를 저장
- 이때 단순한 정답 라벨(0/1: hard label)뿐만 아니라 확률 분포(soft label)까지 포함할 수도 있음
- 작은 모델 학습
- Teacher Model이 만든 soft labels를 사용해 작은 모델을 훈련
- 원래 데이터셋보다 더 풍부한 정보(teacher의 확신 정도 등)를 포함하므로 학습 효율이 높아짐
종류
- Soft Label Distillation: Teacher가 예측한 확률 분포를 Student가 학습하도록 함.
- Hard Label Distillation: Teacher의 예측 결과를 정답처럼 사용하여 학습.
- Intermediate Layer Distillation: Teacher의 중간 계층 정보를 Student에게 전달하여 학습 성능을 향상.
- Self-Distillation: Teacher와 Student가 동일한 모델 구조를 가지며, 더 많이 학습된 버전이 덜 학습된 버전을 가르침.
그럼 지도학습이고 확장성이 없다?
- 전통적인 KD는 확장성이 떨어지지만, 최근에는 비지도 학습이나 자기지도 학습과 결합한 KD 방법도 연구되고 있다.
- Semi-supervised KD
- Self-distillation Teacher와 Student가 같은 모델: 학습이 덜 된 모델이 Teacher 역할을 하고, 더 발전한 버전이 Student 역할을 하는데, 같은 모델이 자기 자신을 개선하는 형태라서 추가적인 외부 Teacher 없이도 학습이 가능하다.
- Zero-shot KD
- Step-by-Step Distillation (본 논문) 추론 과정을 함께 증류하여 확장성 확보
LLM의 성능을 이기지는 못하지만 속도 최적화&API 비용 절감을 위해 가벼운 모델을 만들기에 좋아서 다양한 AI 서비스가 사용중
- DeepSeek, Microsoft Azure AI, OpenAI GPT 경량 모델 등
abstract
- 대형언어모델(LLM)을 배포하는 것은 메모리 효율성이 낮고 연산 비용이 높아서 현실적으로 어렵다
- 그래서 나온 Distillation(큰 모델 예측결과로 작은 모델 학습시키는 방식)
- 하지만 LLM과 동등한 성능을 달성하기 위해 대량의 훈련 데이터가 필요
Distilling step-by-step이라는 새로운 메커니즘
- 작은 모델을 훈련하여 LLM보다 높은 성능 달성
- 기존보다 더 적은 훈련 데이터를 사용
- LLM이 생성한 추론 과정을 추가적인 지도 정보로 활용하여 작은 모델을 multi-task framework 방식으로 훈련
주요 결과
- _훨씬 적은 양의 라벨/비라벨 훈련 데이터_를 사용하면서도 더 나은 성능
- few-shot LLM과 비교했을 때 _훨씬 작은 모델 크기_로도 더 나은 성능
- 전체 데이터의 80% + fine-tuned 770M T5이 540B PaLM 모델을 능가
- 기존에는 동일한 T5 모델이 데이터를 100% 사용하고도 LLM의 few-shot 성능을 따라잡기 어려웠다.
 모델 크기도 훨씬 작은데 데이터도 덜 필요하고 태스크도 더 잘하는 ㅇㅁㅇ
모델 크기도 훨씬 작은데 데이터도 덜 필요하고 태스크도 더 잘하는 ㅇㅁㅇ
Distilling step-by-step
LLMs to reason about their predictions to train smaller models in a data-efficient way
프레임워크
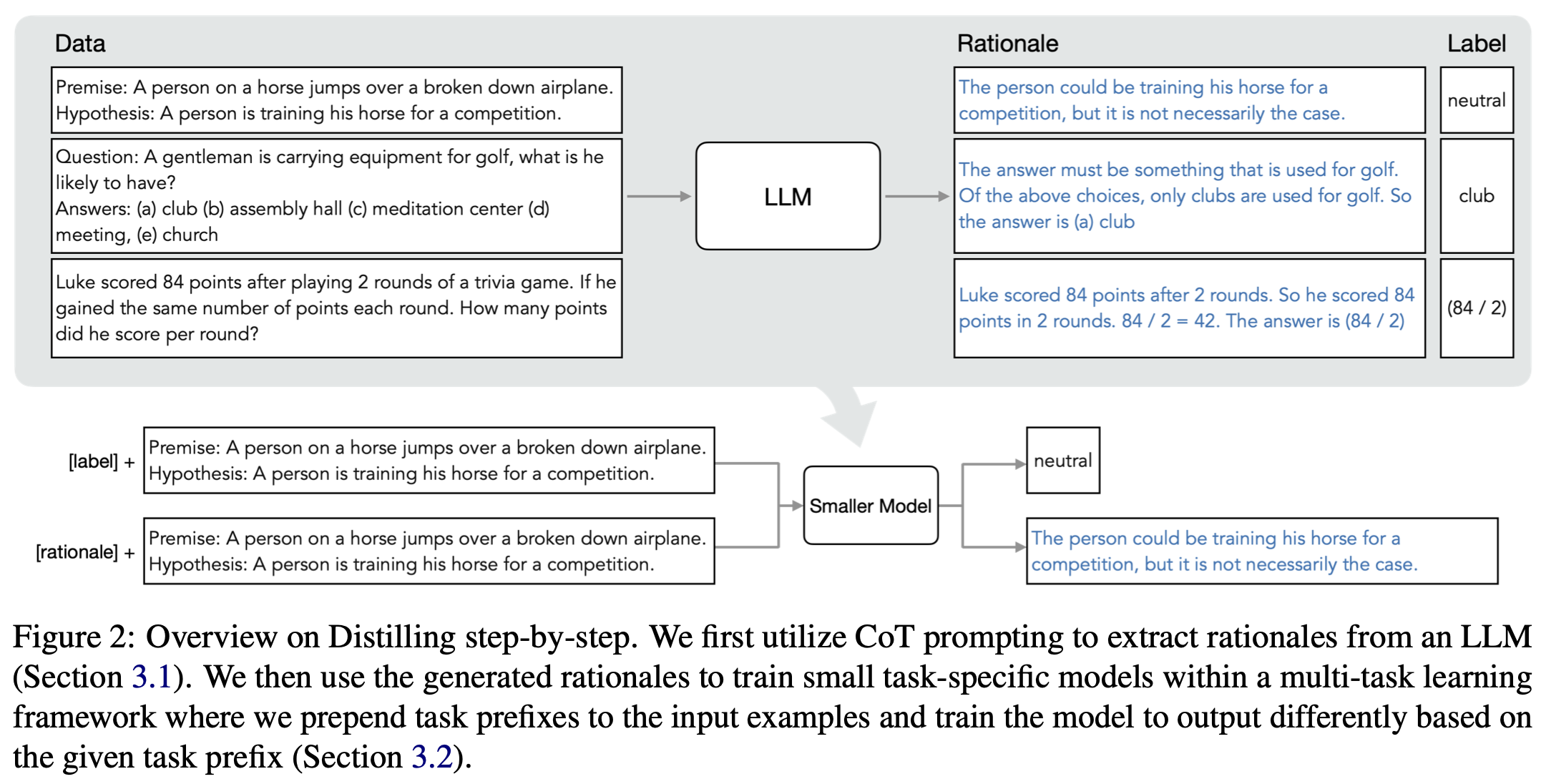
step 1. unlabeled 데이터셋이 주어졌을 때, LLM에게 출력 라벨과 함께 해당 라벨을 정당화하는 추론 과정을 생성하도록 프롬프트 설계
step 2. 생성된 rationales와 라벨을 함께 활용하여 작은 모델을 학습시킨다. rationale은 입력과 출력 사이의 매핑을 설명하는 더 풍부하고 상세한 정보를 제공한다.
- 두 단계 모두 LLM을 활용함.
Extracting rationales from LLMs
CoT를 활용한다. 
- 라벨이 없는 데이터셋 \(x_i \in D\)이 주어졌을 때, 태스크가 어떻게 해결되어야 하는지를 설명하는 프롬프트 탬플릿 \(p\)를 먼저 구성한다.
- 각 프롬프트는 \((x^p, r^p, y^p)\)의 세 가지 요소로 이루어져 있다.
- \(x^p\): example input
- \(r^p\): corresponding label
- \(y^p\): user-provided rationale (왜 \(x^p\)가 \(y^p\)로 분류되는지)
- 위의 그림에서는 초록색 하이라이트가 $x^p$, 파란색 하이라이트가 \(y^p\)
- 각 $x_i$를 $p$에 더해서 프롬프트 완성
- LLM은 예제를 담은 프롬프트 $p$를 기반으로 추론 과정\(\hat r_i\) & 라벨 \(\hat y_i\)을 생성한다.
Training smaller models with rationales
데이터셋을 다음과 같이 정의한다. \[D = {(x_i, y_i)}^N_{i=1}\]
\(x_i\): input \(y_i\): output label
- 모든 형태의 입출력을 지원하지만, 실험에서는 자연어로 제한한다.
- 분류, 자연어 추론, 질문 응답 등의 태스크를 수행 가능
Standard finetuning and task distillation
- 지도학습: 사전 훈련된 모델을 지도학습 데이터를 사용하여 파인튜닝
- 작업별 증류: 라벨이 없는 경우, task-specific distillation 기법 사용
- LLM이 teacher model 역할을 하여 훈련용 가짜(pseudo) 라벨을 생성한다.
- 즉, 실제 라벨 $y_i$ 대신 노이즈가 포함된 가짜 라벨 $\hat y_i$를 생성하여 사용한다.
- 작업별 증류: 라벨이 없는 경우, task-specific distillation 기법 사용
두 가지 경우 모두에서, 작은 모델 $f$는 라벨 예측 손실(label prediction loss)을 최소화하도록 학습된다. \[L_{label} = \frac {1}{N} \sum ^N _{i=1} \ell(f(x_i), \hat y_i)\]
- 여기서 \(\ell\)은 예측된 토큰과 목표 토큰 사이의 cross-entropy loss
- 표현을 단순화하기 위해, 위의 수식에서 \(\hat y_i\)는 다음과 같이 정의한다.
- 지도학습에서는 사람이 주석한 실제 라벨 \(y_i\) 의미
- 작업별 증류에서는 LLM이 생성한 가짜 라벨 \(\hat y_i\) 의미
Multi-task learning with rationales
더 명확한 입출력의 연결을 위해, 추론 과정까지 학습시키기
- 가장 직관적으로는: 추론 과정 \(\hat r_i\)를 추가 인풋으로 사용
- 그러나 이 설계 방식에서는 먼저 LLM이 근거를 생성한 후에야 모델 $f$가 예측을 수행할 수 있다. 즉, 배포 시점에서도 LLM이 필요하게 되어, 실제 적용이 제한될 수 있다.
Unfortunately, this design requires an LLM to first generate a rationale before the f can make a prediction. The LLM is still necessary during deployment, limited its deployability.
- 작은 모델 $f$는 입력+근거를 받아서 정답을 예측하도록 학습됨
- 예측을 수행하기 위해 반드시 근거 \(\hat r_i\)를 입력으로 받아야 함
- 하지만 \(\hat r_i\)는 LLM이 생성하는 것이므로, 모델을 실행할 때마다 먼저 LLM을 호출하여 근거를 생성해야 함..
대안적 접근
multi-task learning으로 접근
- 작은 모델이 자체적으로 근거까지 생성할 수 있도록 학습한다.
In this work, instead of using rationales as additional model inputs, we frame learning with rationales as a multi-task problem.
근거(추론 과정)를 모델의 추가 입력으로 사용하는 대신, 근거 학습을 다중 작업 학습 문제로 설정한다. 즉, 모델 \(f(x_i)\)를 학습하여 단순히 정답 라벨 \(\hat y_i\)만 예측하는 것이 아니라, 입력 텍스트 \(x_i\)가 주어졌을 때 이에 대한 근거 \(\hat r_i\)도 함께 생성하도록 한다. \[L = L_{label}+\lambda L_{rationale}\]
- \(L_{rationale}\)은 rationale generation loss
- 모델이 예측을 수행하는 과정에서 중간 추론 단계를 학습하도록 유도
- 작은 모델 \(f(x_i)\)를 학습할 때, 출력으로 정답뿐만 아니라 근거도 생성하도록 학습
- 이를 본 논문에서는 Distilling step-by-step 기법이라고 부른다.
Task Prefixes
모델 학습 시, 입력 데이터에 task prefixes를 추가한다. 예를 들어, 입력 데이터 앞에 다음과 같은 태그를 붙인다.
이러한 방식으로 학습된 작은 모델은 입력 데이터가 주어졌을때, 앞의 태그를 보고 생성할 대상을 정할 수 있게 된다.
Experiments
Distilling step-by-step vs. Standard Finetuning 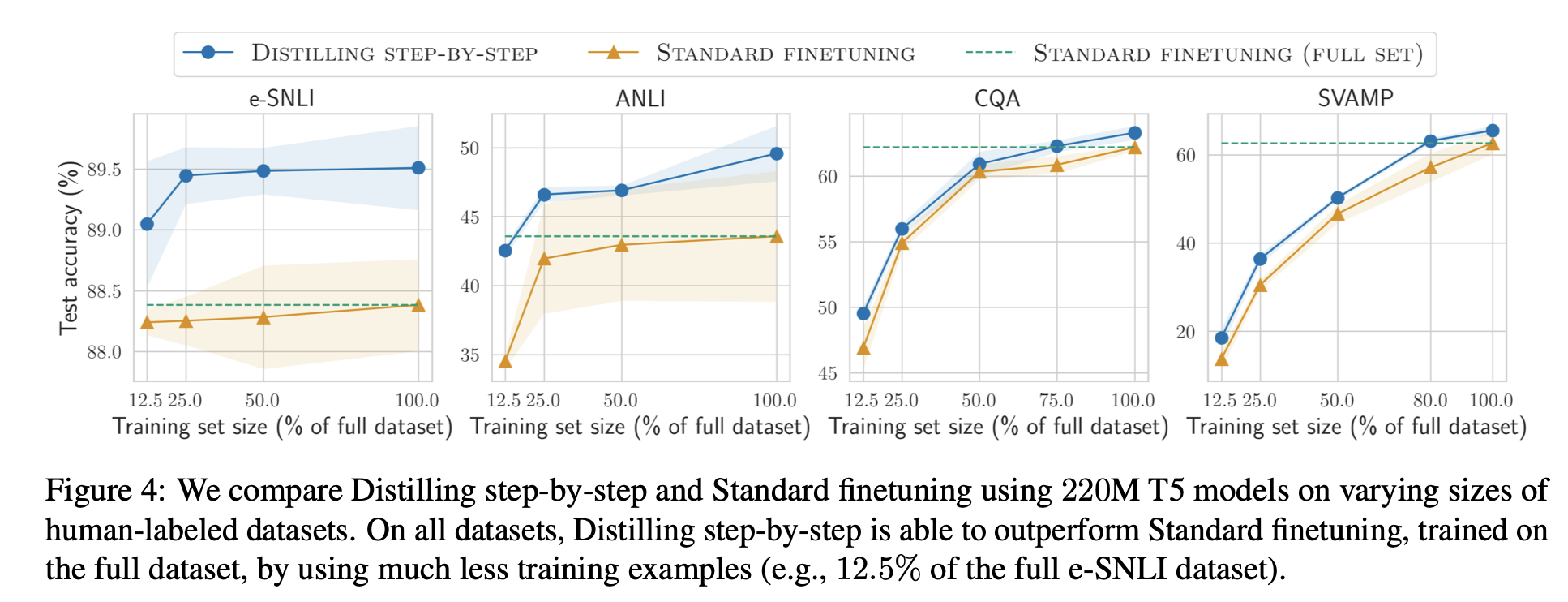
- 220M T5 모델
- 다양한 크기의 사람이 라벨링한 데이터로 학습 결과
- Distilling step-by-step 방식은 훨씬 적은 학습 데이터를 사용하면서도 standard finetuning을 능가함
- 전체 데이터셋(ANLI)의 12.5%만 사용해도 성능이 훨씬 좋음
Distilling step-by-step vs. Standard task distillation 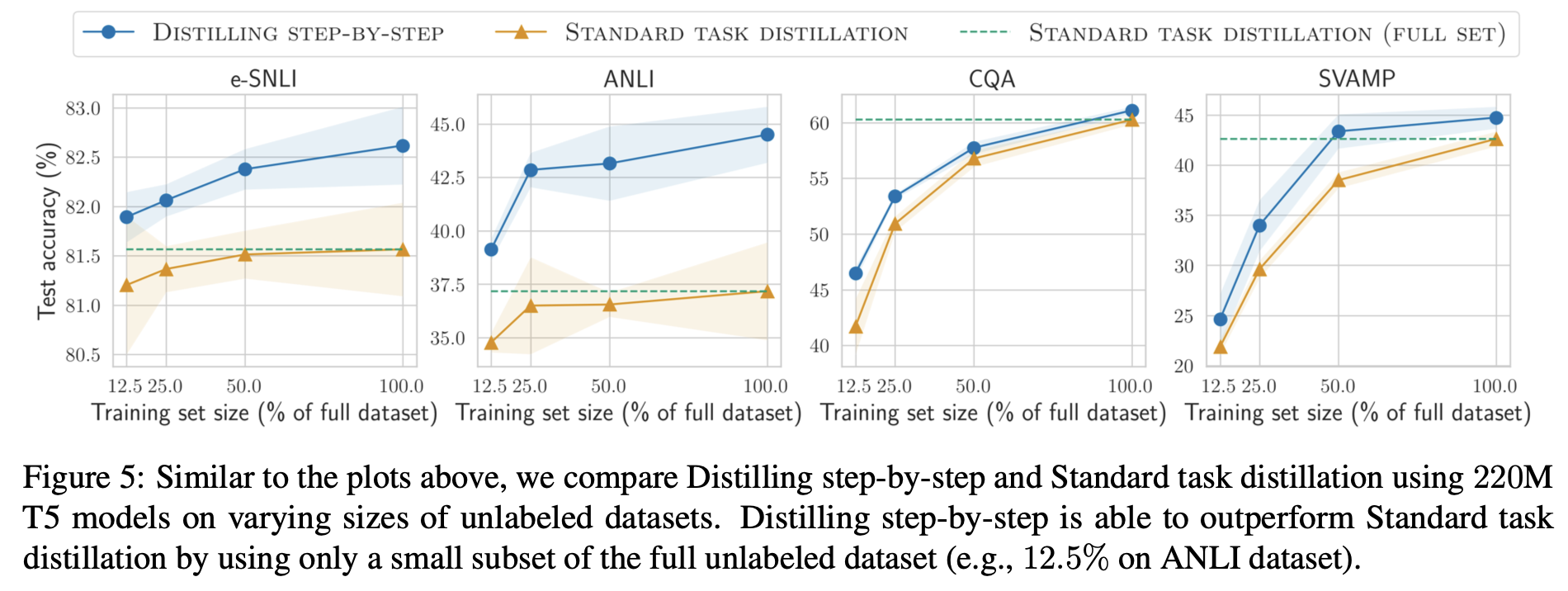
- 220M T5 모델
- 다양한 크기의 비지도 데이터셋으로 학습 결과
- Distilling step-by-step 방식은 훨씬 적은 학습 데이터를 사용하면서도 standard task distillation을 능가함
- 비지도 학습 환경에서도 효율적으로 학습 가능
결론: 비유하자면
- standard finetuning: 문제를 직접 풀면서 공부하는 방식. 많은 데이터가 필요함.
- standard task distillation: LLM이 대충 정답을 알려주고 공부하는 방식. 비지도 데이터 활용 가능하지만, 비효율적 (풀이과정 학습하지 않는다.)
- distilling step-by-step: 문제 풀이 과정을 학습하여 적은 문제만 풀어도 효율적으로 성능 향상 가능
