REALM: Retrieval-Augmented Language Model Pre-Training
REALM: Retrieval-Augmented Language Model Pre-Training
2020.02
- retriever 도 학습을 하면 QA 성능이 매우 높아짐
- retriever 와 reader를 한번에 학습할 수 있음
- retriever를 pretraining에서 수행하는 모델 제안
main contribution
- retriever 와 reader 를 한번에 학습하는 end-to-end 모델
- 쿼리를 넣어 답을 찾는 과정을 두 단계로 분리
- neural knowledge retriever
abstract
REALM의 핵심: unsupervised text의 performance-based signal을 사용하여 retriever를 학습시킨다.
가장 적절한 문서를 검색하는 것이 주요 목적
비지도 학습 방식으로는 처음으로 사전 학습하는 방법을 제시: MLM, retrieval step을 역전파 학습
언어모델의 perplexity를 개선하는 검색은 보상을 주고 정보가 없는 검색은 패널티를 주는 방식
Open-domain Question Answering 태스크에서 효과적, sota \
일반적으로 딥러닝 모델은 역전파(backpropagation)라는 방법을 사용해서 학습
모델의 출력을 올바른 정답과 비교하고, 그 차이를 줄이도록 모델의 내부 가중치(parameters)를 조정하는 방식
그런데 REALM에서는 단순히 신경망의 매개변수만 학습하는 게 아니라, 문서를 검색하는 과정(retrieval step)도 함께 학습한다. 즉, 모델이 “어떤 정보를 검색해야 하는지”까지 최적화하는 것 \
method
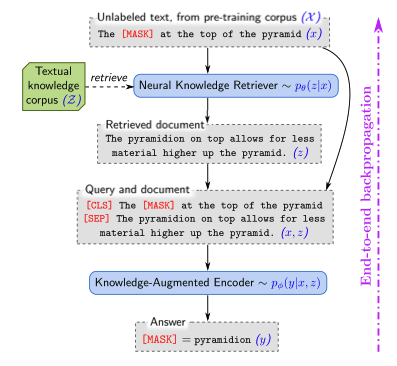
- 알맞은 문서인지 평가하는 방법: MIPS(Maximum Inner Product Search)
- document z와 Input x의 임베딩 벡터 간의 내적값을 계산
- 알맞은 retrieve 방법을 latent variable language model로 모델링
- marginal likelihood를 최적화하여 학습
- Knowledge Augmented Encoder
- 외부지식을 추가적으로 활용하는 인코더
예를 들어 위의 그림에서 model이 “the ___ at the top of the pyramid”의 빈칸을 채워야하는 경우, retriever는 “The pyramidion on top allows for less material higher up the pyramid.”라는 document를 선택하면 보상을 받는다. \ (Retrieved Document, Query and document 사이)
검색 과정을 하나의 확률적 선택 과정으로 보고, 학습을 통해 점점 더 좋은 검색 결과를 찾을 수 있도록 만듦.
REALM’s generative process
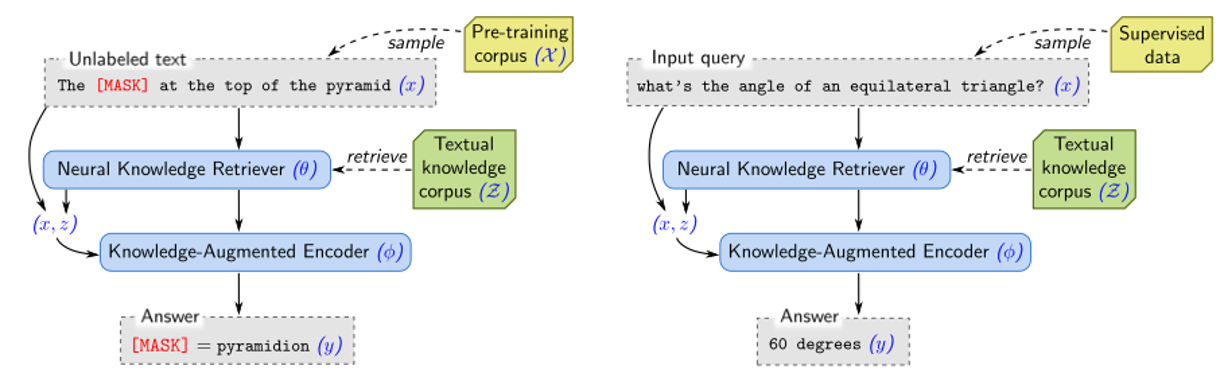
REALM은 입력 x가 주어지면 가능한 출력 y에 대한 확률분포 p(y|x)를 학습
- pre-training 단계
- MLM(Masked Language Modeling) 수행
- 입력 x는 일부 단어가 가려진 문장
- 모델은 가려진 단어 y를 예측하는 작업을 학습
- fine tuning 단계
- Open Domain QA 문제를 학습
- 입력 x는 질문, 출력 y는 정답
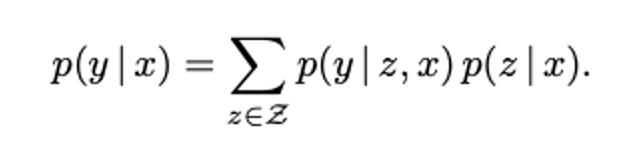 어떤 문서 z를 참고해야 할지를 확률적으로 결정하는 과정
어떤 문서 z를 참고해야 할지를 확률적으로 결정하는 과정
확률 분포 \(p(y|x)\)를 두 단계로 분해하여 학습: retrieve–then-predict를 공식화
- retrieve step (문서 검색)
- 입력 x가 주어지면 지식 코퍼스 Z에서 관련 문서 z를 검색
- \[p(z|x)\]
- predict step (답변 생성)
- 검색된 문서 z와 원래 입력 x를 바탕으로 답변 y를 생성
- \[p(y|z,x)\]
- 이때 어떤 문서 z가 가장 좋은 문서인지 미리 알 수 없기 때문에 모든 가능한 문서 z에 대해 확률을 합산(marginalization)
=> 먼저 여러 개의 문서 z 를 검색하고, 각 문서별로 답변을 생성한 뒤, 각 문서에 대한 확률 \(p(z∣x)\)을 곱해서 최종적으로 가장 가능성 높은 정답을 고르는 과정
Knowledge Retriever: \(p(z|x)\) 정의
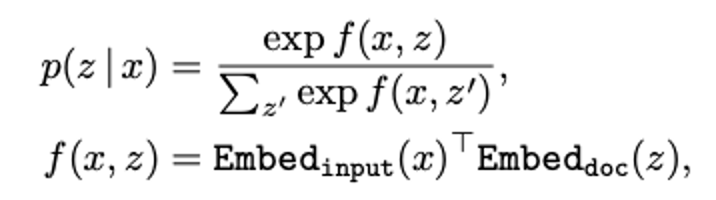
- 검색 모델 정의 Retrieval 과정은 내적을 기반으로 문서와 질문의 관련성을 측정하는 모델을 사용: Dense Inner Product Model
- \[f(x,z)\]
- 입력 x와 문서 z 사이의 유사도 점수
- softmax 분포: 문서 전체에 대해 유사도를 계산한 후 softmax를 적용하여 확률분포로 변환
- 유사도 점수 계산
- Embed_input(x): 입력 x를 벡터로 변환하는 함수
- Embed_doc(z): 문서 z를 벡터로 변환하는 함수
- 둘을 내적
- \[f(x,z)\]

- 임베딩 방법 BERT 기반 Transformer를 사용하여 질문과 문서를 벡터로 변환
- 입력 질문을 BERT 형식으로 변환
- 두 개의 텍스트를 하나로 합침
 BERT 모델에 통과시킨 후 선형변환을 적용하여 최종 임베딩 변환
BERT 모델에 통과시킨 후 선형변환을 적용하여 최종 임베딩 변환
- 입력 (질문) 임베딩 변환
- 문서 (후보 문서) 임베딩 변환
- W: 차원을 줄이기 위한 선형 변환 행렬
- 모델의 학습 가능 매개변수: BERT Transformer 파라미터, Projection Matrices
Knowledge-Augmented Encoder: \(p(y|z, x)\) 정의
입력 x와 검색된 문서 z를 하나의 시퀀스로 결합한 후 Transformer를 사용하여 답을 생성
- pre-training의 경우
- MLM 사용
- Transformer의 출력 벡터와 단어 임베딩의 내적을 계산하여 MASK 토큰 예측
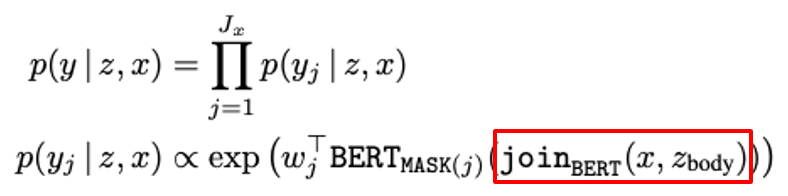
- \(J\): 가려진 MASK 토큰 개수
- \(y_j\): j번째 MASK 토큰이 원래 갖고 있던 단어
입력 x와 검색된 문서 z를 하나의 시퀀스로 결합한 후 Transformer를 사용하여 답을 생성
- fine-tuning의 경우
- 답변이 검색된 문서 z 안에 존재한다고 가정
- 정답이 연속된 단어(스팬)로 이루어져 있다고 가정
- MLP(Multi-Layer Perceptron), 즉 피드포워드 신경망을 사용하여 정답 스팬 예측

\(h_{start}\): 시작 위치 예측
\(h_{end}\): 끝 위치 예측
\(S(z, y)\): 문서 z에서 정답 y와 일치하는 Span들의 집합 \
training
정답 y의 log-likelihood log p(y|x)를 최대화
발생한 이슈들 2가지 소개 \
- 지식 검색 과정 계산 문제
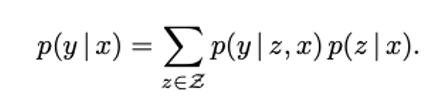
- 모든 확률 합산: 문서 전체 집합 Z가 크면 계산량이 너무 많음
- 해결: 검색 확률이 높은 상위 k개 문서만 고려
- 검색을 위한 MIPS

- 효율적으로 사용하기 위해 모든 문서의 벡터를 미리 만들어서 빠르게 검색할 수 있도록 인덱싱 해야 함
- 모든 문서 z를 벡터로 변환해서(Embed_doc(z)) MIPS 검색 인덱스에 저장
- 하지만 학습이 계속될수록 문서 임베딩 함수의 파라미터가 계속 업데이트되기 때문에 최신 모델과 불일치(stale) 문제 발생
- 해결: 검색 인덱스 주기적 업데이트
experiment
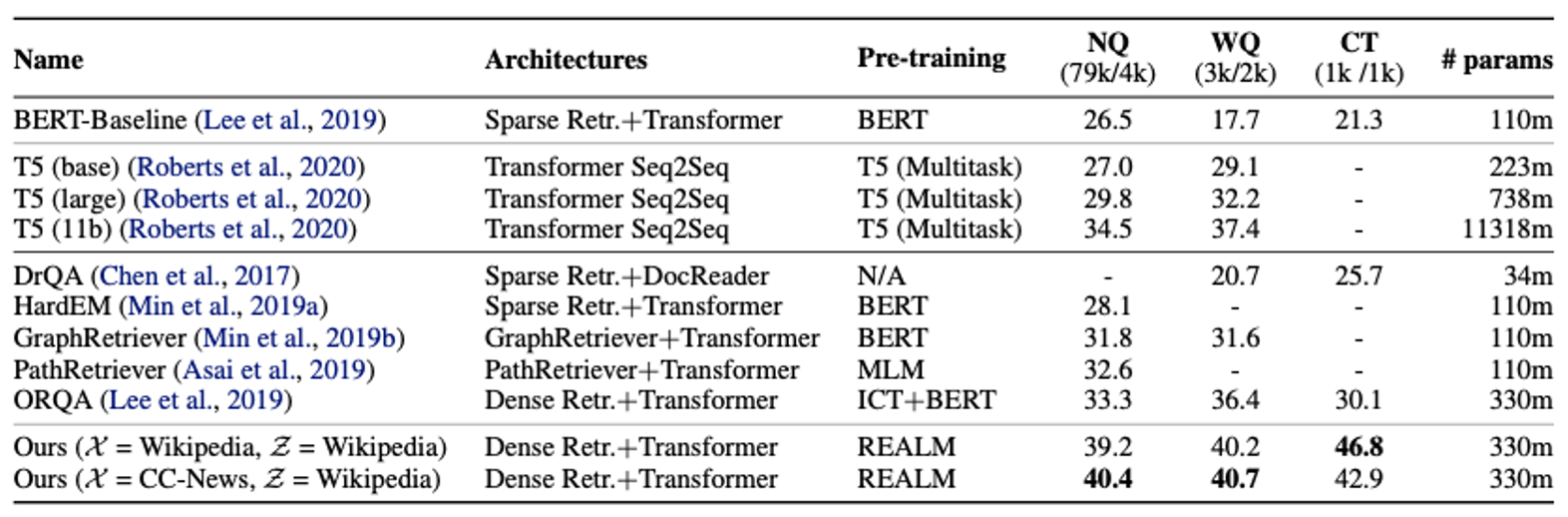 T5는 REALM과 달리 사전학습에서 SQuAD의 추가 MRC dataset에 접근한다는 점을 유의
T5는 REALM과 달리 사전학습에서 SQuAD의 추가 MRC dataset에 접근한다는 점을 유의
결론
- 기존의 언어모델보다 30배 작은 크기
- 검색 과정도 학습 가능한 방식으로 통합 (end-to-end learning)
- 검색과 답변 생성을 하나의 신경망으로 연결
- 검색 과정도 비지도 학습을 활용해 학습
