Adaptive-RAG: Learning to Adapt Retrieval-Augmented Large Language Models through Question Complexity
abstract
- QA 작업에 RAG가 유용하지만 기존 접근 방식은 단순한 질문에도 불필요한 계산 비용이 들거나, 복잡한 다단계 질의를 적절하게 처리하지 못하는 문제가 있다
- 질의의 복잡도에 따라 가장 적절한 전략을 자동으로 선택하는 적응형 QA 프레임워크 : Adaptive-RAG
- 질의 복잡도를 예측하는 분류기(classifier)
- 작은 규모의 언어모델을 학습시켜 들어오는 질문의 복잡도를 자동으로 분류
- 실제 모델 예측 결과와 데이터셋의 내재적 편향을 기반으로 학습됨
obtained from actual predicted outcomes of models and inherent inductive biases in datasets.
- 내재적 귀납적 편향이란, 데이터셋이 가지고 있는 특정한 경향성 또는 패턴을 의미(질의 패턴)
- 단순한 질문의 경우 불필요한 검색을 생략 / 복잡한 질문의 경우 다단계 검색을 적용
- single step 검색, 반복 검색, 검색 생략 등 다양한 전략을 혼합하여 적용할 수 있다
- 오픈 도메인 QA 데이터셋을 사용하여 모델을 검증
- 다양한 질의 복잡도를 포함하는 데이터셋에서 기존 방법보다 효율성과 정확도가 향상됨을 확인
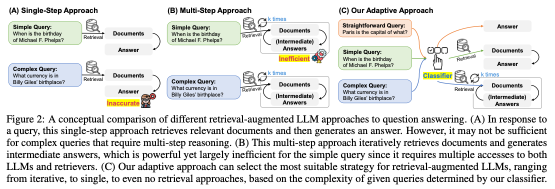
-> 단순한 쿼리만 있는 것도 아니고 복잡한 쿼리만 있는 것도 아닌데 하나의 방법으로 rag를 사용하는건 비효율적이다!
그러니까 상황에 맞는 rag를 적용하자!
method
1. 직관적 쿼리
Non-Retrieval QA
검색을 사용하지 않는 QA 방식
고효율: 검색 과정이 없으므로 빠르게 답변 생성
대형 LLM의 효과 활용: 최신 대형 LLM들은 이미 방대한 지식을 내부적으로 포함하고 있음
내부 지식이 최신이 아니거나 특정 세부 정보를 포함하지 않을 경우 오답을 생성할 가능성
2. 단순 쿼리
Single-Step Approach for QA
외부 지식 소스 D로부터 얻은 지식 d를 활용
\(d = Retriever(q;D)\)
검색: q와 관련성이 가장 높은 문서 d를 찾는다 (이때 기존의 검색 모델을 사용)
(q, d) 쌍을 얻게 되면 이를 LLM의 입력으로 함께 제공
\(\bar a = LLM(q, d)\)
LLM의 내부 지식이 부족한 경우를 보완
정확성과 최신성 향상
3. 복잡한 쿼리
Multi-Step Approach for QA
n차(다단계) 검색 & 추론
초기 질의 q에서 시작
매 단계 i 에서 새로운 문서 d_i 가 검색 모델을 통해 검색됨
\(d_i = Retriever(q, c_i; D)\)
LLM은 이전 단계의 문서 및 답변을 참고하면서 새로운 입력을 구성 => 추가 context $c_i$ \
\((d_1, d_2, ..., d_{i-1}, \bar a_1, \bar a_2, ..., \bar a_{i-1})\)
최종적으로, 누적된 정보를 바탕으로 답변 생성 \[\bar a_i = LLM(q, d_i, c_i)\]
복잡한 질의를 효과적으로 처리할 수 있지만 계산 비용은 높다
training
쿼리의 복잡성은 어떻게 평가?
질의와 복잡도(Complexity) 간의 라벨이 주어진 데이터셋(Annotated Dataset)이 존재하지 않기 때문에 자동으로 학습 데이터셋을 구축하는 전략을 제안
complexity classifier (복잡도 분류기)
질의 q를 입력으로 받아 해당 질의의 복잡도를 예측, o: class label
$o = Classifier(q)$
직관적: A, 단순: B, 복잡: C
라벨링 규칙
Non-Retrieval 로 진행했을때 정답이 맞게 나오면 => A라벨 부여
1번이 실패했지만 multi/single step 중 하나라도 맞게 나오면 => 더 간단한 모델에 우선순위 부여
1,2번이 모두 실패하면 QA 데이터셋이 내재적으로 포함하는 귀납적 편향을 활용
귀납적 편향이라는건 데이터셋의 특성을 반영한다는건데, 그냥 벤치마크 데이터셋의 종류에 따라 일괄적으로 분류하는 것 \
Single-Hop 데이터셋 => 단일검색으로 해결 가능하도록 설계된 qa 데이터셋이기 때문에 => 일괄적으로 B라벨 부여
Multi-Hop 데이터셋 => 다중 문서 간 추론이 필요한 qa 데이터셋이기 때문에 => C라벨 부여
데이터셋
- Single-hop
- SQuAD v1.1
- Natural Questions
- Trivia QA
- Multi-hop
- MuSiQue
- HotpotQA
- 2WikiMultiHopQA
experiment
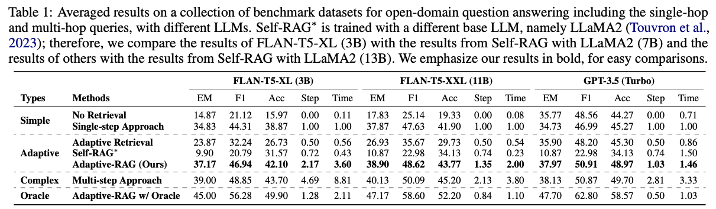 F1: 정답과 모델 답변 사이 겹치는 단어의 수
F1: 정답과 모델 답변 사이 겹치는 단어의 수
EM: 정답과 모델 답변이 동일한지
Acc: 모델 답변에 정답이 포함되어 있는지
Time과 Step을 봤을 때, Multi-step approach가 훨씬 비용이 많이 든다
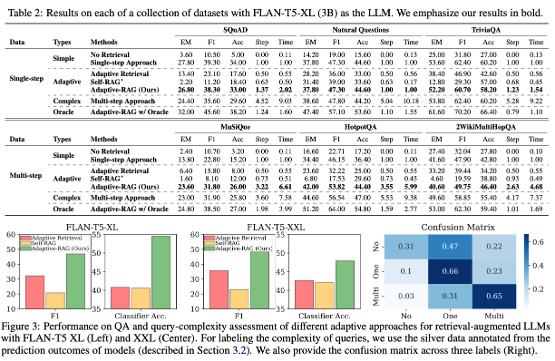 oracle classifier를 사용한 adaptive-rag의 성능과도 비교하여 더욱 향상된 classifier도 검증
oracle classifier를 사용한 adaptive-rag의 성능과도 비교하여 더욱 향상된 classifier도 검증
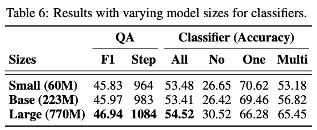 모델 크기는 성능에 크게 영향을 미치지 않음
모델 크기는 성능에 크게 영향을 미치지 않음
오분류에 대한 성능 개선 필요
다른 분류 방식을 사용해도 되는데 이건 향후 과제로
결론: 쿼리 난이도에 따라 다른 rag 전략을 선택하는 적응형 모델~
