T-RAG: LESSONS FROM THE LLM TRENCHES
T-RAG 2024.06
RAG + 파인튜닝 > 하이브리드 접근법
abstract
- RAG를 구축하는 것은 비교적 간단하지만, 이를 견고하고 신뢰할 수 있는 응용 프로그램으로 만드는 데는 상당한 커스터마이징과 애플리케이션 도메인에 대한 깊은 지식이 필요하다
기업의 비공개 문서를 대상으로 llm 기반 QA 어플리케이션을 만든 경험을 공유하는 논문
조직 내의 entity 계층 구조를 tree 구조로 나타낸다 이 트리 구조는 사용자 쿼리가 조직 계층 구조 내의 엔터티와 관련된 경우, 컨텍스트를 보완하기 위해 텍스트 설명을 생성하는 데 사용됩니다.
- 평가 결과, 특히 “건초 더미 속 바늘 찾기” 테스트(Needle in a Haystack test)에서, 단순 RAG나 단순한 미세 조정 방식보다 이러한 조합이 더 나은 성능을 발휘하는 것으로 나타났다.
- 실제 LLM 어플리케이션 구축하는 경험에서 얻은 교훈 공유
T-RAG

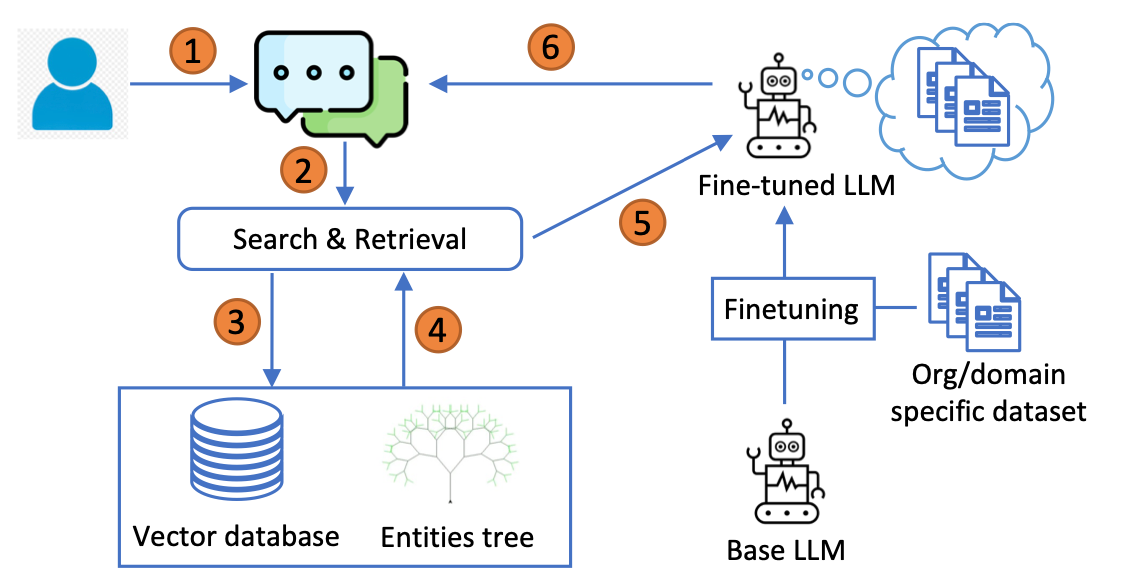
- 기존의 사전학습된 llm 대신 미세 조정된 llm 버전을 사용한다
- 주요 특징: context 검색을 위한 벡터 데이터베이스 외에 엔터티 트리(Entities Tree)를 포함한다
검색 방법
검색 과정에서, T-RAG는 벡터 데이터베이스에서 검색된 컨텍스트를 추가적으로 보강하기 위해 엔터티 트리를 사용
- 파서 모듈이 사용자 쿼리를 분석하여 조직 내 엔터티 이름과 일치하는 키워드를 검색
- 하나 이상의 일치 항목이 발견되면, 트리에서 각 일치 엔터티에 대한 정보를 추출하여 해당 엔터티와 조직 계층 내 위치를 설명하는 텍스트 설명문으로 변환
- 생성된 정보는 벡터 데이터베이스에서 검색된 문서 조각들과 결합되어 컨텍스트를 형성
method
데이터셋 준비 ->
원본 pdf 문서를 텍스트 형식으로 변환 후 문서를 chunk로 나눔
llama-2 모델에게 해당 chunk와 관련된 질문과 답변을 생성하도록 요청하여 질의응답 pair를 만듦
최종 데이터셋은 1614개의 QA pair
LLM finetuning -> QLoRA 사용
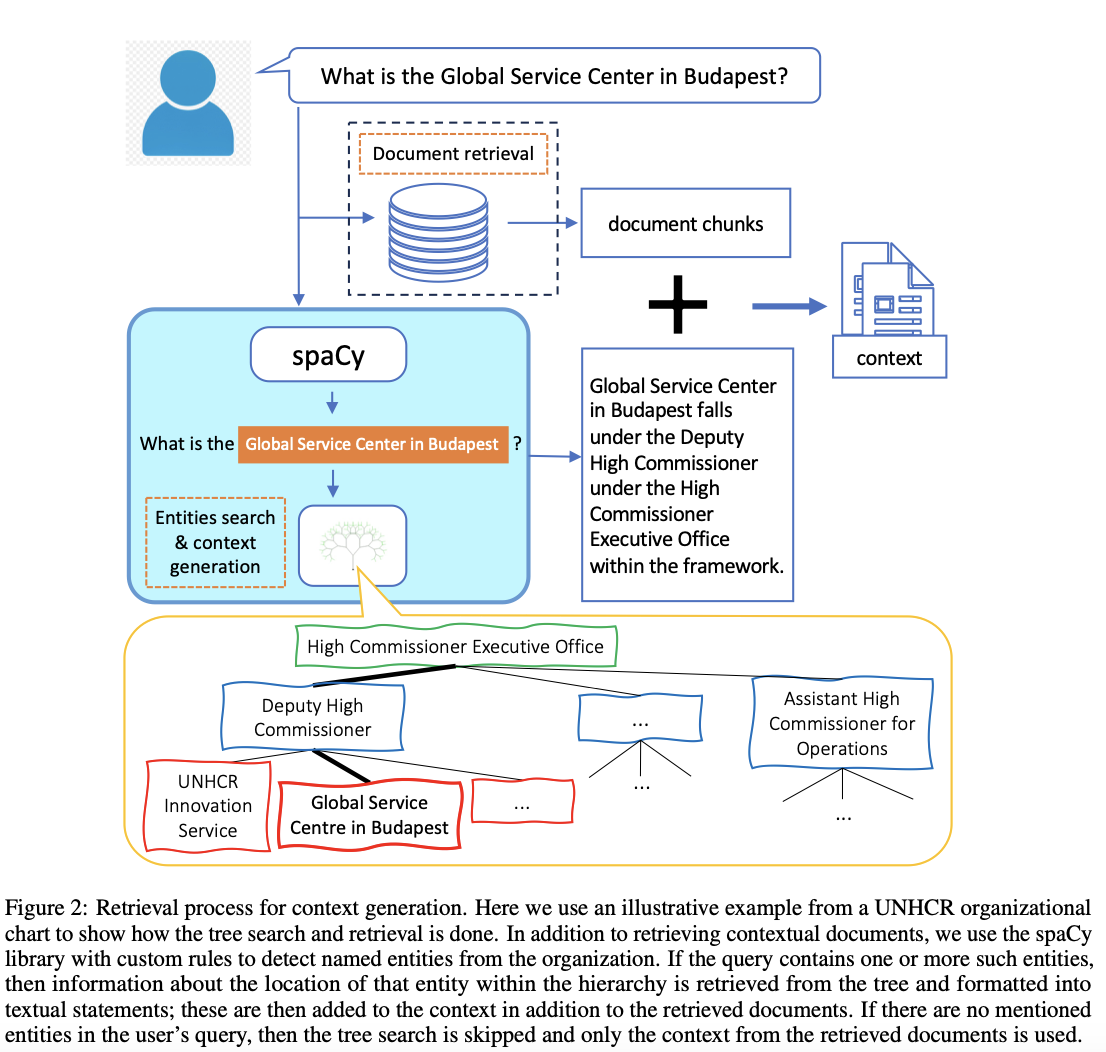
Tree Graph for Entities -> 문서에는 조직의 계층 구조와 부서를 나타내는 조직도가 포함되어 있었다
- 엔터티 트리는 조직 내 엔터티와 이들의 계층 구조 내 위치에 대한 정보를 저장
- 트리의 각 노드는 하나의 엔터티를 나타냄
- 상위 노드는 해당 엔터티가 속한 그룹을 나타냄
이 방식으로 트리는 조직의 각 엔터티에 대한 전체 계층 구조를 인코딩하며, 특정 엔터티에서 시작해 상위 카테고리까지의 경로를 추적하거나, 해당 엔터티 아래에 속한 다른 엔터티들을 탐색할 수 있다
이 정보는 검색 단계에서 추출되어 텍스트 설명문으로 변환됨
벡터 데이터베이스에서 검색된 문서 chunk와 함께 context에 포함됨 –> context 강화 효과
사용자 쿼리에 조직의 엔터티와 관련된 정보만 포함시키기 위해, 사용자 쿼리에서 조직의 엔터티가 언급되었는지, 그리고 어떤 엔터티가 언급되었는지를 감지해야 함
만약 사용자 쿼리에 조직의 엔터티가 전혀 언급되지 않았다면, 트리 검색을 건너뛰고 벡터 데이터베이스에서 검색된 문서 컨텍스트만 사용
조직과 관련된 명명된 엔터티(named entities)만 감지하는 방법이 필요
-> spaCy 라이브러리를 사용
spaCy는 Named Entity Recognition 기능이 있어서 이를 문서의 특징에 맞게 튜닝
예를 들어, 그림 2에 나타난 사용자 쿼리에서, spaCy는 “Budapest”를 단순히 위치(Location)로 감지하지만, “Global Service Center in Budapest”가 UNHCR 조직 내 엔터티라는 사실은 놓침
이를 해결하기 위해, spaCy 라이브러리에 새로운 카테고리를 정의하고, 문자열 매칭을 사용해 조직에 속한 엔터티를 감지하는 규칙을 추가로 설정
evaluation
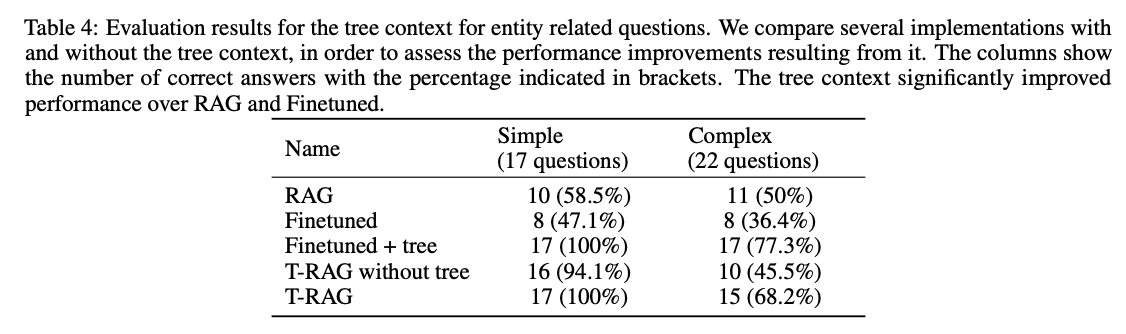
트리 구조를 사용하면 엔터티 관련된 질문을 했을 때 RAG나 파인튜닝된 모델보다 훨씬 성능이 잘 나왔다
Needle in a Haystack 테스트
 이 테스트는 관련 context를 K개의 무관한 context chunk로 둘러싸고 이를 문맥의 다양한 위치에 배치하는 방식
이 테스트는 관련 context를 K개의 무관한 context chunk로 둘러싸고 이를 문맥의 다양한 위치에 배치하는 방식
일반적으로는 관련 context가 중앙에 배치된 경우보다 양 끝에 배치된 경우 더 나은 성능을 보임
RAG: k=10일때 중앙에 배치 » 33.3%로 성능이 크게 감소 같은 조건일때 64.1%의 성능을 보임
RAG 보다 T-RAG의 성능이 안정적임: 컨텍스트 위치나 크기의 영향을 덜 받는다.
결론: Finetuning + RAG는 성능이 좋다~ 유용하게 쓸 수 있는 프로젝트가 있을지도!
