LLaVA: Visual Instruction Tuning
LLaVA 2023.04
abstract
LLM모델을 instruction tuning하는 연구가 많이 이루어지지만, multimodal task에서는 상대적으로 적음
- to use language-only GPT-4 to generate multimodal language-image instruction-following data.
언어만을 인풋으로 받는 GPT4를 사용해서 멀티모달 언어-이미지 instruction following 데이터를 생성
- end-to-end trained large multimodal model that connects a vision encoder and an LLM for general purpose visual and language understanding.
vision encoder와 LLM을 연결해서 시각/언어 이해가 가능한 모델
introduction
dataset generation
GPT-assisted Visual Instruction Data Generation
- simple expanded version image-text pair 를 instruction-following version 으로 확장
이미지 Xv와 이에 대한 캡션 Xc가 있을 때, 이미지 내용을 서술해달라는 질문을 Xq로 한 데이터셋을 생성 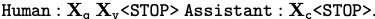 비용은 적지만 다양성과 심도있는 reasoning이 불가하다는 단점이 있었음
비용은 적지만 다양성과 심도있는 reasoning이 불가하다는 단점이 있었음
하지만 이것만으로는 이미지에 대한 깊은 이해가 부족해서 instruction-following dataset을 생성
- image-text pair 데이터를 기반으로 ChatGPT / GPT4를 활용

- Symbolic Representations 1) captions input이 text 전용이기 때문에 이미지를 입력하지 않고 설명으로 준다.
2) bounding boxes
- Response Type 1) Conversation 주어진 이미지에 대해 QA pair 생성 이미지만 보고 알 수 있는 시각적 요소 자체에 대한 질문으로 이루어짐 2) Detailed Description 이미지에 대한 상세한 설명을 GPT4를 통해 생성 3) Complex Reasoning 심층적인 추론을 하는 질문 및 답변을 생성, 단계별로 어떤 논리/그리고 그 이유까지 요구
architecture
pretrained LLM과 Visual Model을 효과적으로 사용하고자 함 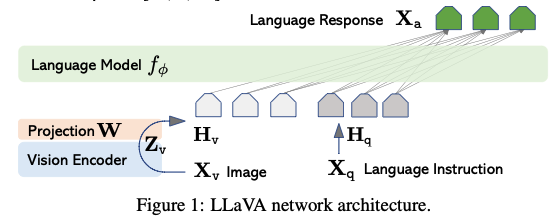
LLM: Vicuna 활용: 당시 instruction following 능력이 가장 우수 Visual Encoder: ViT-Large 14 활용: Pre-trained CLIP visual encoder
이미지 feature를 word embedding space에 연결하기 위해 linear layer(Projection W)를 추가했다. linear layer의 output dimension은 언어 모델의 word embedding space와 같게 설정한다.
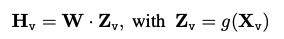
- 이미지 Xv가 입력되면 이를 Zv=g(Xv)로 통과시킨다. 이때 g는 CLIP이다.
- Zv를 language embedding token Hv로 변환
training
 각 이미지에 대해 multi-turn conversation data T는 전체 turn의 횟수
각 이미지에 대해 multi-turn conversation data T는 전체 turn의 횟수
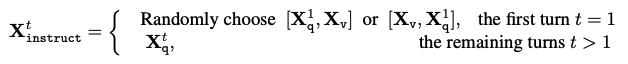
- 첫번째 turn에서는 이미지 feature를 질문 앞에 둘건지 뒤에 둘건지 random하게 결정
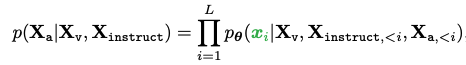
- 학습을 위해 instruction tuning을 수행: auto regressive training objective 사용
- 앞에 나온 token들을 보고 다음 단어를 맞추는 task인데, 기존 언어모델들과 달리 이미지 feature(Xv)를 함께 사용
 위의 예시에서 초록색 부분을 예측해야 함
위의 예시에서 초록색 부분을 예측해야 함 - assistant가 얘기하는 Xa의 loss 계산
- 문장의 끝인 STOP 예측
학습 시 사용하는 데이터에 따라 LLaVA는 two-stage로 학습을 한다. Stage 1: Pre-training for Feature Alignment CC3M 데이터를 595K image-text pair로 필터링
- 여러 턴의 대화가 아닌 single turn으로 구성
- 이미지 설명을 요청하는 instruction을 주고 기존의 캡션을 대답으로 사용
- stage1에서는 visual encoder와 LLM의 weight은 고정(freeze)시키고, 오직 projection matrix만 학습시킨다
- 이를 통해 이미지 feature는 사전 학습된 LLM의 word embedding과 align된다 –> frozen LLM에 호환되는 visual tokenizer를 학습하는 과정
Stage 2: Fine-tuning End-to-End visual encoder만 freeze시키고 LLM과 projection layer 두 모듈을 학습한다. 두 가지 시나리오를 고려 1) multimodal chatbot 아까 만든 158K language-image instruction following data를 이용해 fine tuning한 chatbot 2) science QA scienceQA benchmark에서 고안한 방법을 테스트 질문과 context를 instruction으로 주고 맞춰야 하는 답변으로 추론과 정답 데이터를 준다
experiment
 GPT4, BLIP2, OpenFlamingo와 비교했을 때, BLIP2와 OpenFlamingo는 이미지를 설명하는 데에 중점을 둔 반면 80K의 데이터를 사용하였음에도 GPT4 비슷한 수준의 추론 능력을 보인다.
GPT4, BLIP2, OpenFlamingo와 비교했을 때, BLIP2와 OpenFlamingo는 이미지를 설명하는 데에 중점을 둔 반면 80K의 데이터를 사용하였음에도 GPT4 비슷한 수준의 추론 능력을 보인다.
결론: llm+visual encoder 합쳐서 텍스트랑 이미지 정보 동시에 처리할 수 있는 멀티모달 모델~
