DDPM: Denoising Diffusion Probabilistic Models
DDPM: Denoising Diffusion Probabilistic Models
2023년 게시글 - 수정 필요
Diffusion Probabilistic Models
- data에 임의의 noise를 더해주는 forward process와 noise를 제거하는 reverse process를 학습하는 모델
- forward process (diffusion process): data에 noise를 추가하는 과정으로, markov chain을 통해 점진적으로 noise를 더해나간다.
- reverse process: gaussian noise에서 시작하여 점진적으로 noise를 제거해가는 과정
Prerequisite
What is ‘Diffusion’?
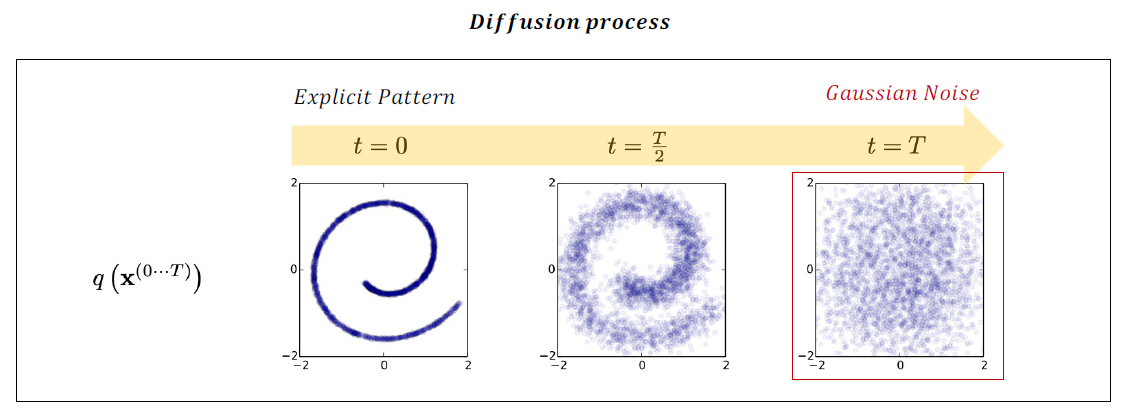 특정한 데이터의 패턴이 서서히 반복적인 과정을 거쳐 와해되는 과정(농도가 균일해지는)을 ‘Diffusion process’라 명명
특정한 데이터의 패턴이 서서히 반복적인 과정을 거쳐 와해되는 과정(농도가 균일해지는)을 ‘Diffusion process’라 명명
비지도학습 방법론으로 활용되고 있음
Markov Chain
: Markov 성질을 갖는 이산확률과정
- Markov 성질: “특정 상태의 확률(t+1)은 오직 현재(t)의 상태에 의존한다”
- 이산확률과정: 이산적인 시간(0초, 1초, 2초, ..) 속에서의 확률적 현상
ex. “내일의 날씨는 오늘의 날씨만 보고 알 수 있다.” (내일의 날씨는 오로지 오늘의 날씨 만을 조건부로 하는 확률적 과정)
Latent Variable Model
: 잠재 변수 모델
관찰 가능한 데이터에서 직접 측정할 수 없는 ‘잠재 변수’를 이용해 모델을 구성하는 방식이다. 잠재 변수는 직접 관찰되지 않지만 관찰 가능한 데이터의 분포를 설명하는 데 중요한 역할을 하는 변수이다. 예를 들어, 사용자의 구매 패턴에서 각각의 구매 이벤트는 관찰 가능하지만, 사용자의 숨겨진 구매 선호도는 직접적으로 관찰할 수 없는 잠재 변수가 될 수 있다.
잠재 변수 모델은 관찰 데이터의 분포를 효과적으로 설명하고 복잡한 패턴을 파악하는 데 널리 사용된다. 잠재 변수를 사용하면 데이터의 차원을 줄일 수 있다(차원 축소된 데이터가 input이 된다).
DDPM의 forward process에서는 천 번의 iteration을 거쳐 noise를 더하는데, 이때 그 많은 과정을 하나하나 관측하지 않는다는(못 할수도 있음) 의미에서 그 변수를 모두 잠재 변수라고 하는 것이다.
직접적인 접근을 하지 않는 근사 문제이다.
KL Divergence
: 두 확률 분포 P, Q가 얼마나 다른지 측정하는 방법
P는 사후, Q는 사전 분포를 의미한다.
원본 데이터 확률 분포와 근사 분포와의 로그 차이 값의 기대값을 구하고자 한다. \[D_{\mathrm{KL}}(P \| Q)=\sum_{x \in \mathcal{X}} P(x) \log \left(\frac{P(x)}{Q(x)}\right)\]
Overview of Generative Models
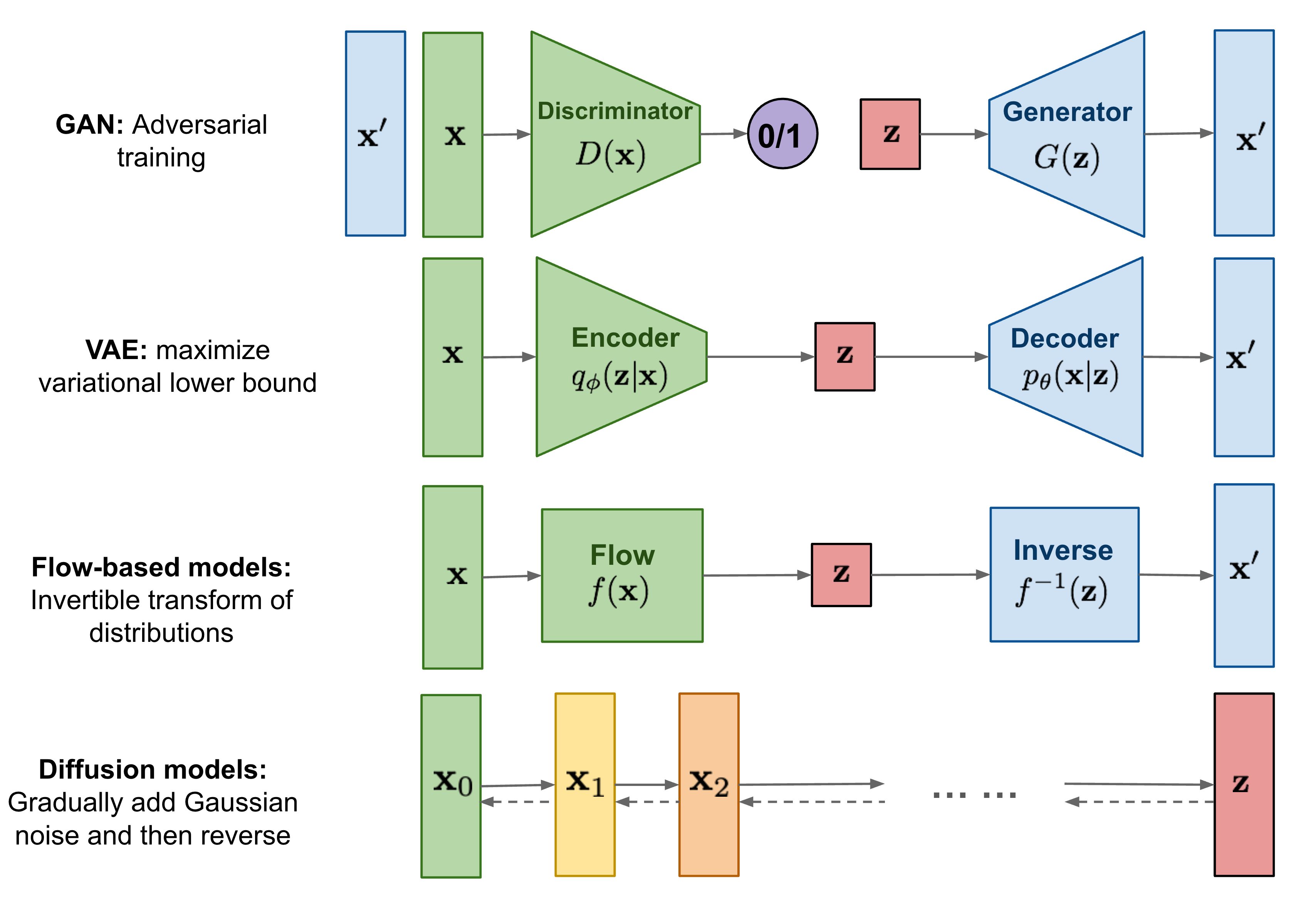
- 반복적인 변화(iterative transformation)를 활용한다는 점에서 Flow-based models와 유사
- 분포에 대한 변분적 추론을 통한 학습을 진행한다는 점은 VAE와 유사
- VAE는 encoding하는 network와 latent code를 바탕으로 이미지를 decoding network 모두를 학습하는 반면,
- Diffusion 모델은 이미지를 encoding하는 forward process는 fix된 채 이미지를 decoding하는 reverse process - single network만을 학습한다.
- 최근에는 Diffusion 모델의 학습에 Adversarial training을 활용하기도 함
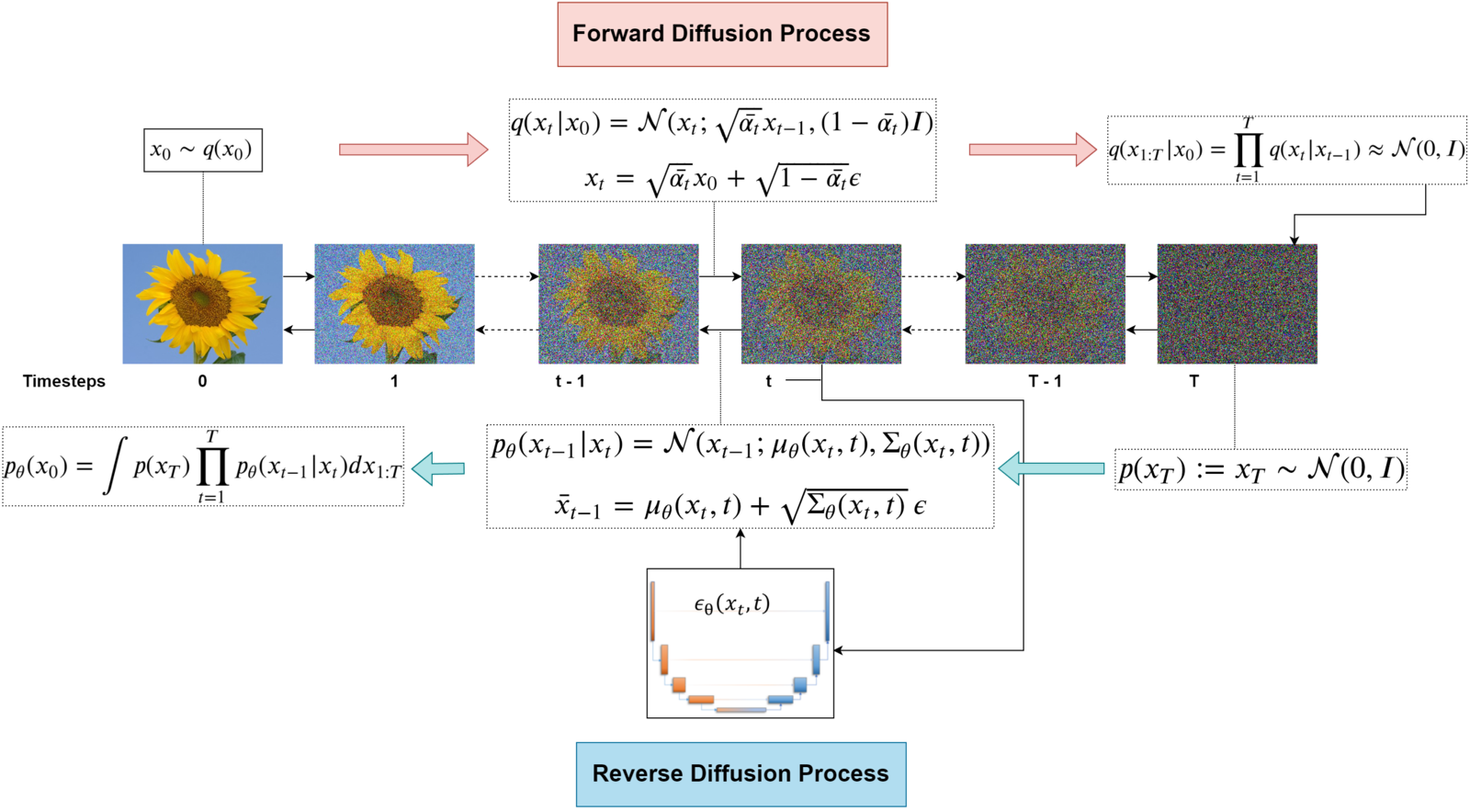
Forward Process (Diffusion Process)
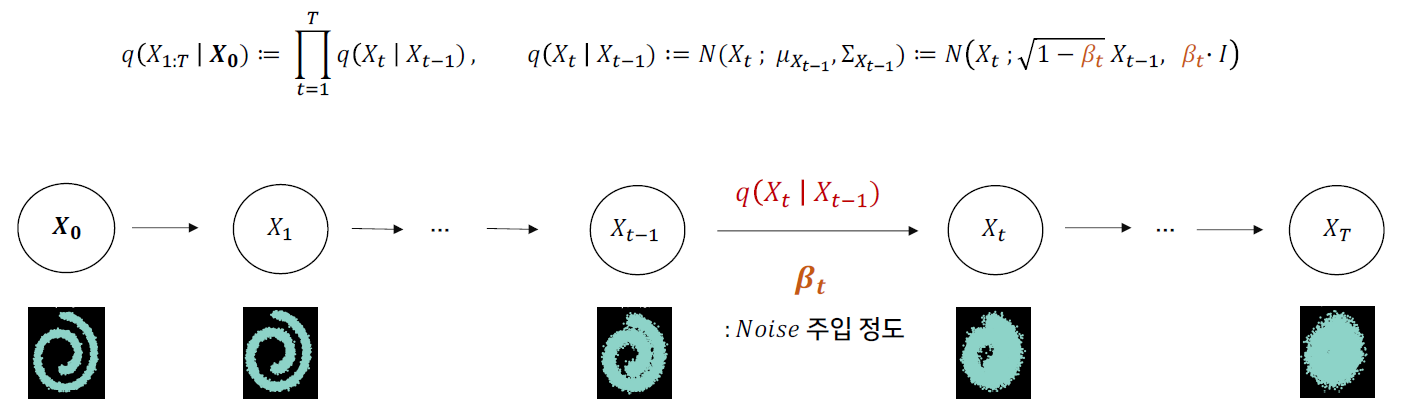
- markov chain으로 data에 점전적으로 noise를 추가하는 과정이다.
Forward Process Equation
- Gaussian Distribution(\(\mathcal{N}\))에서 나온 noise를 data에 더해준다.
- \(q\left(\mathbf{x}_{1: T} \mid \mathbf{x}_0\right)\) 수식을 보면, 우도(likelihood)의 형태를 보이고 있다.
- β는 diffusion rate(variance schedule)로 분산이 divergence하는 것을 방지해준다.
- 하지만 위의 β를 이용해서 수식을 전개하면 0~T의 모든 수식을 step by step으로 전개해야 하여 메모리 소모가 크고 시간도 오래 걸린다.
- 이를 해소하기 위해 α를 이용한다.
- \(X_t\)는 Gaussian Distribution에서 나오는 값이기 때문에 평균을 기준으로 어느 정도 분산으로 치우친 값을 가질 것이다.
- α를 이용하여 한 번에 전개가 가능하다.
T steps of diffusion
\(q\left(\mathbf{x}^{(0 \cdots T)}\right)=q\left(\mathbf{x}^{(0)}\right) \prod_{t=1}^T q\left(\mathbf{x}^{(t)} \mid \mathbf{x}^{(t-1)}\right)\)
Reverse Process (Denoising Process)
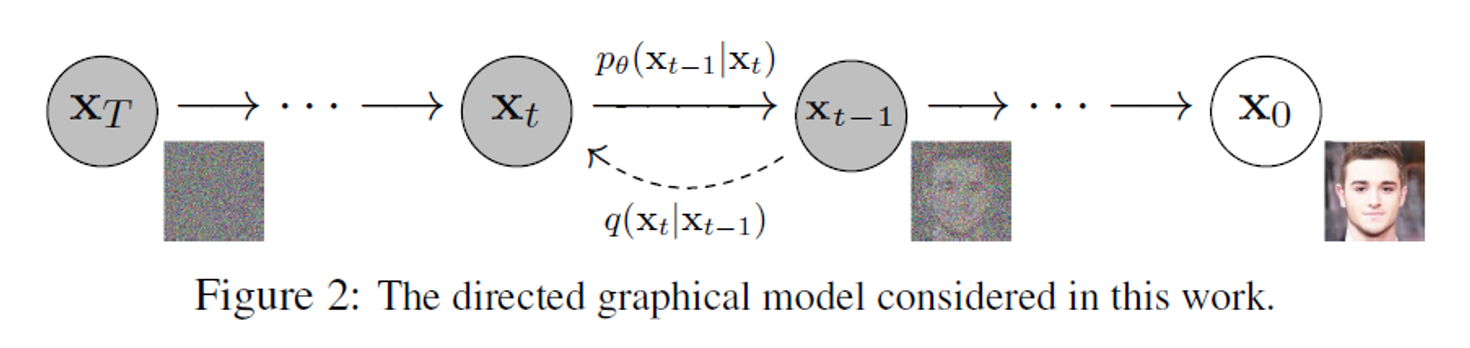 Diffusion process의 역 과정을 학습한다.
Diffusion process의 역 과정을 학습한다.
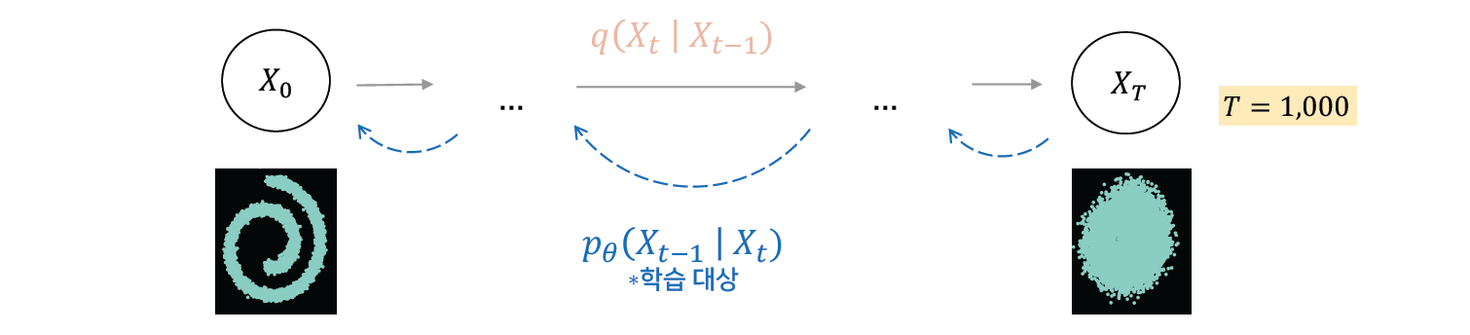 Gaussian noise를 제거해가며 특정한 패턴을 만들어가는 과정이다. \[p_\theta\left(X_{0: T}\right):=p\left(X_T\right) \prod_{t=1}^T q\left(X_{t-1} \mid X_t\right), \quad p_\theta\left(X_{t-1} \mid X_t\right):=N\left(X_{t-1} ; {\left.\mu_\theta\left(X_t, t\right), \Sigma_\theta\left(X_t, t\right)\right)}\right.\]
Gaussian noise를 제거해가며 특정한 패턴을 만들어가는 과정이다. \[p_\theta\left(X_{0: T}\right):=p\left(X_T\right) \prod_{t=1}^T q\left(X_{t-1} \mid X_t\right), \quad p_\theta\left(X_{t-1} \mid X_t\right):=N\left(X_{t-1} ; {\left.\mu_\theta\left(X_t, t\right), \Sigma_\theta\left(X_t, t\right)\right)}\right.\]
mean&variance를 잘 approximate할 수 있도록 학습하는 것이 목표이다.
학습 대상은 \(\mu_\theta\left(X_t, t\right)\), \(\Sigma_\theta\left(X_t, t\right)\)이다.
\(\begin{aligned} \operatorname{Loss}_{\text {diffusion}} & :=D_{K L}\left(q\left(z \mid x_0\right) \| P_\theta(z)\right)+\sum_{t=2} D_{k L}\left(q\left(x_{t-1} \mid x_t, x_0\right) \| P_\theta\left(x_{t-1} \mid x_t\right)\right)-E_q\left[\log P_\theta\left(x_0 \mid x_1\right)\right] \\ & :=\text {Negative log likelihood }\left(=\mathbb{E}_{x_T \sim q\left(x_T \mid x_0\right)}\left[-\log p_\theta\left(x_0\right)\right]\right) \end{aligned}\)
Diffusion(not DDPM)의 Loss는 log likelihood를 maximize시켜야 한다.
VAE
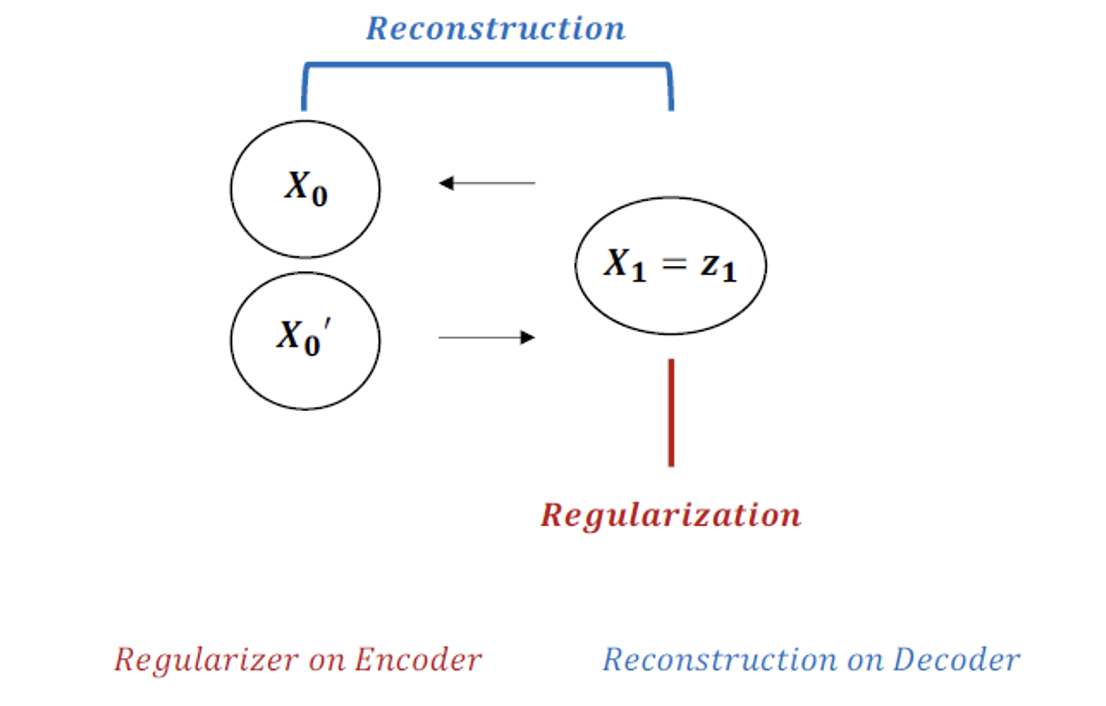 \[\operatorname{Loss}_{V A E}=D_{K L}\left(q(z \mid x) \| p_\theta(z)\right)-E_{z \sim q(z \mid x)}\left[\log P_\theta(x \mid z)\right]\]
\[\operatorname{Loss}_{V A E}=D_{K L}\left(q(z \mid x) \| p_\theta(z)\right)-E_{z \sim q(z \mid x)}\left[\log P_\theta(x \mid z)\right]\]
Diffusion
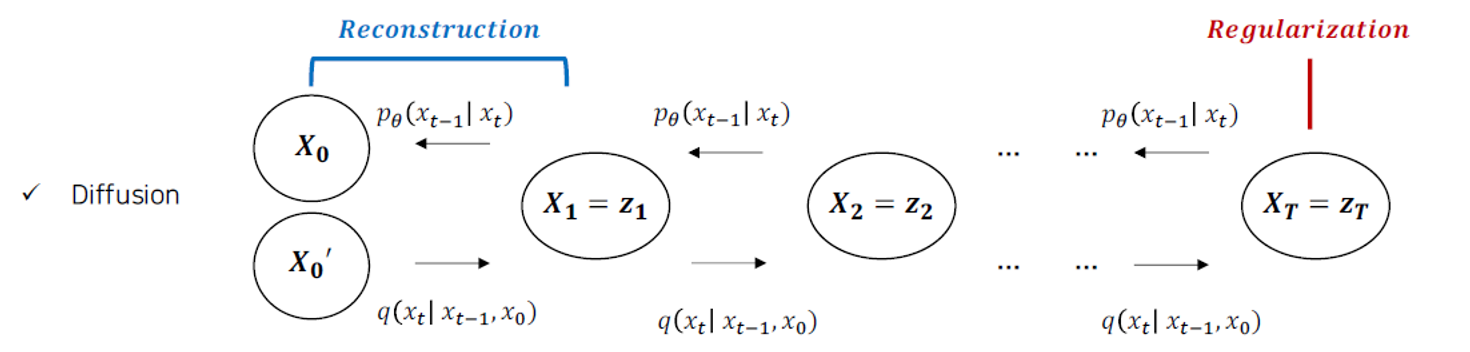
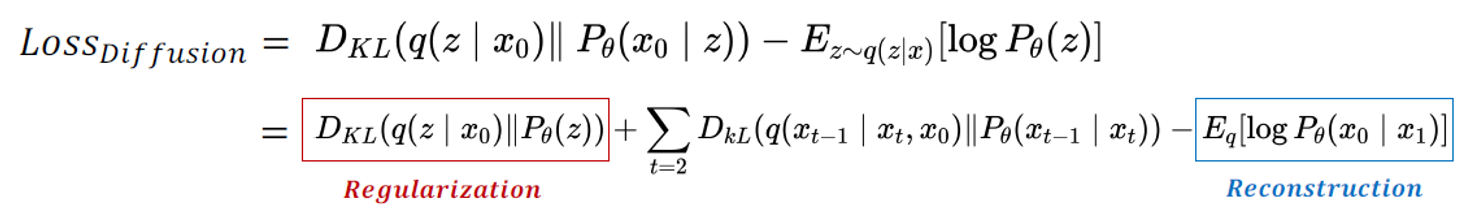 Regularization과 Reconstruction의 구조는 동일하게 가지고 있다. Diffusion은 Denoising Process를 가지고 있다는 것이 차이점이다.
Regularization과 Reconstruction의 구조는 동일하게 가지고 있다. Diffusion은 Denoising Process를 가지고 있다는 것이 차이점이다. 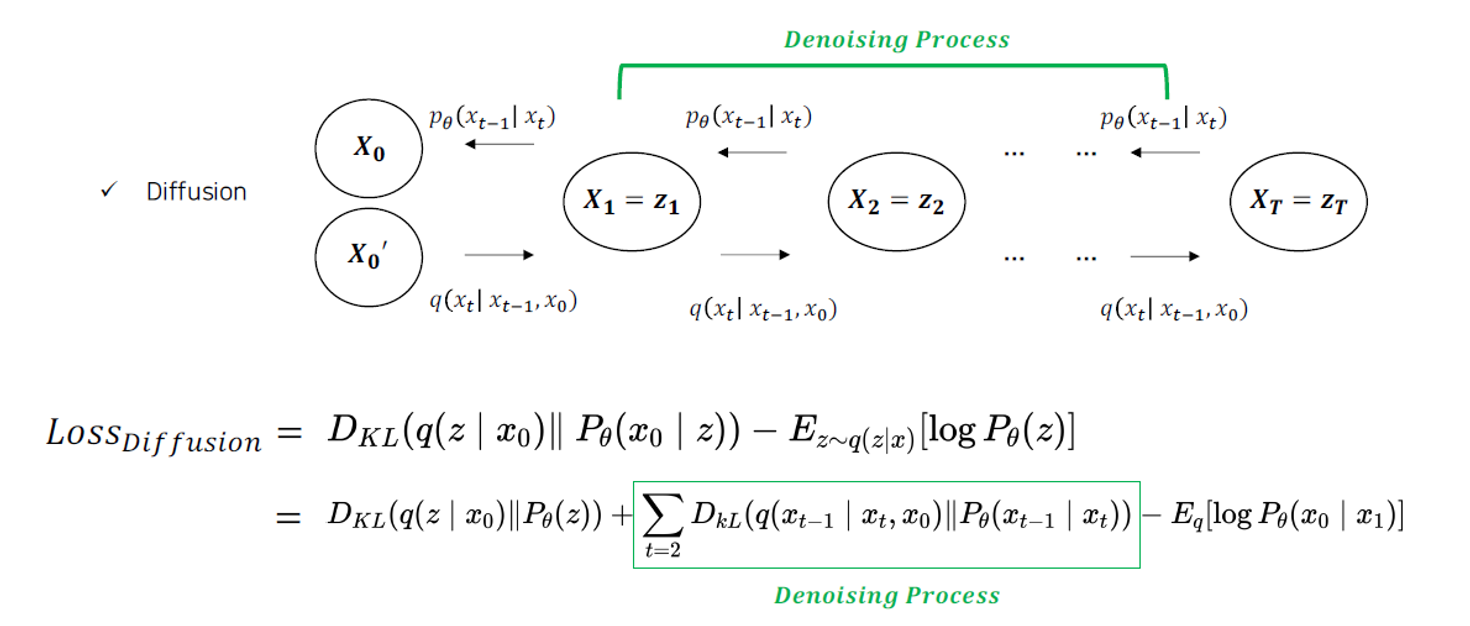 Denoising Process에서 KL Divergence가 이용되고 있다. P라는 reverse process는 q라는 reverse process를 최대한 approximate할 수 있도록 학습하는 것이 보여진다.
Denoising Process에서 KL Divergence가 이용되고 있다. P라는 reverse process는 q라는 reverse process를 최대한 approximate할 수 있도록 학습하는 것이 보여진다.
+) \(P_θ\)가 U-net의 output
DDPM
1. 학습 목적식에서 Regularization term 제외(\(L_T\))
굳이 학습시키지 않아도 fixed noise scheduling으로 필요한 ‘isotropic gaussian’(등방성; 방향과 상관없음) 획득 가능하기 때문이다. 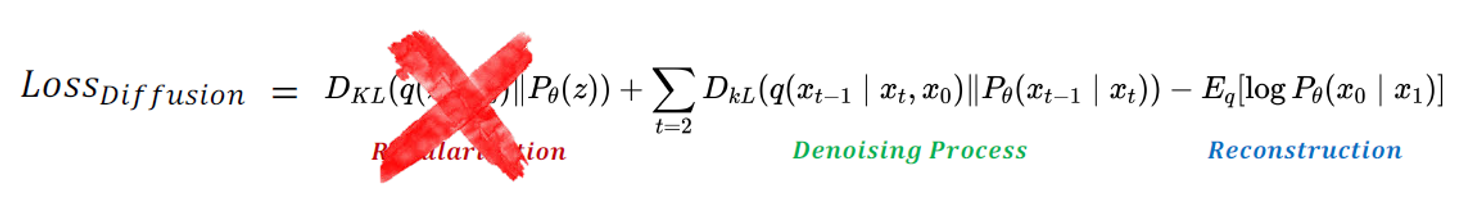 \[L_T = D_{KL}(q(x_T|x_0)||p(x_T))\]
\[L_T = D_{KL}(q(x_T|x_0)||p(x_T))\]
p가 generate하는 noise \(x_T\)와 q가 \(x_0\)라는 데이터가 주어졌을 때 generate하는 noise \(x_T\)간의 분포 차이
이 term은 원래 VAE에서 posterior가 prior(가우시안 분포)를 따르도록 강제하는 loss이다. DDPM에서 forward process는 \(x_T\)를 항상 가우시안 노이즈로 가정하기 때문에 \(L_T\)는 항상 0에 가까운 상수가 된다.
(둘 사이의 KL divergence를 구하는 의미가 없다) ⇒ 학습과정에서 무시
2. Denoising Process의 목적식 재구성
1) 분산의 상수화
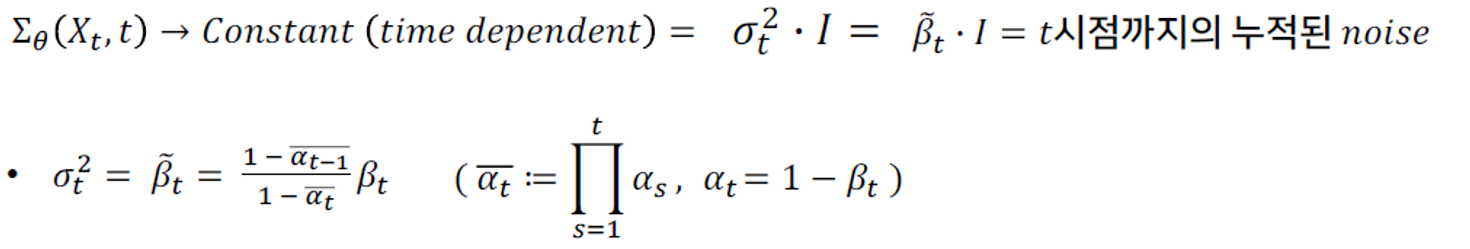
원래 mean & variance를 학습했다면, 이제는 mean만 학습해도 된다.
2) Denoising matching
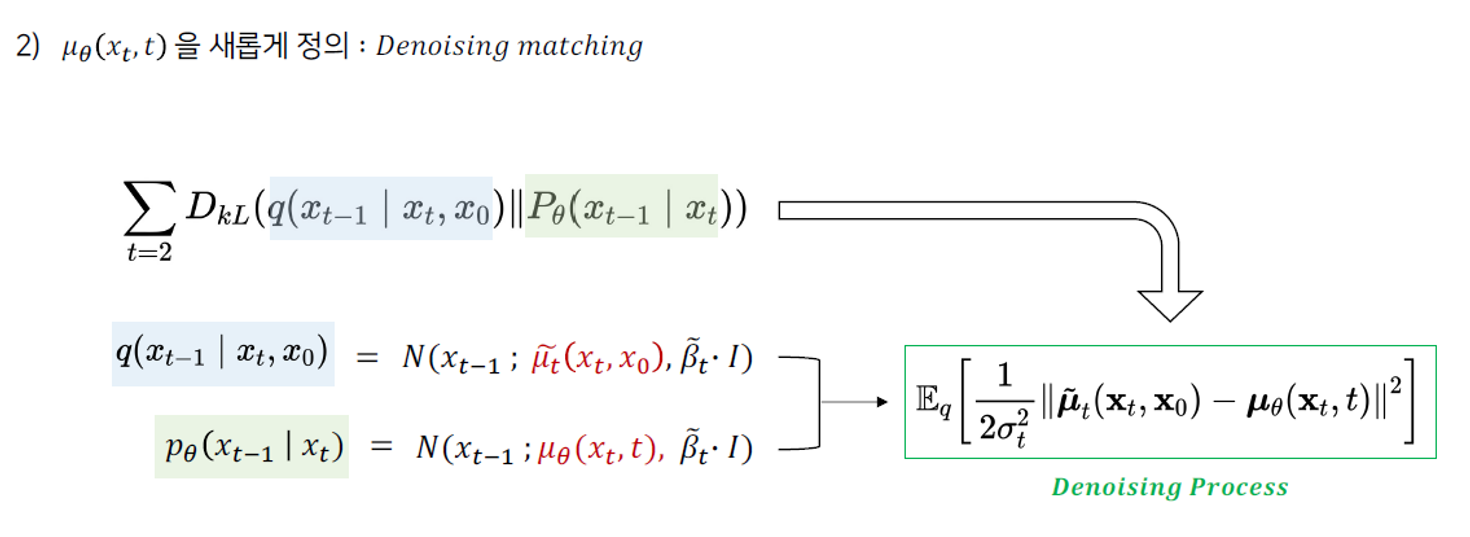 Diffusion process와 Denoising process의 noise를 하나의 식으로 합친다.
Diffusion process와 Denoising process의 noise를 하나의 식으로 합친다.
결국 DDPM model(\(Ⲉ_θ\))이 학습해야 하는 것은 주어진 t시점의 noise()뿐이다.
이처럼 각 시점의 다양한 scale의 gaussian noise를 예측해, denoising에 활용하고자 하는 것이 DDPM의 지향점이다.
Loss Function 유도
\(L_{t-1}=\sum_{t>1}D_{KL}(q(x_{t-1}|x_t, x_0)||p_θ(x_{t-1}|x_t))\)
p와 q의 reverse/forward process의 분포 차이. 이들을 최대한 비슷한 방향으로 학습한다.
\(q(x_{t-1}|x_t, x_0)\) \(p_θ(x_{t-1}|x_t)\) 모두 가우시안(정규 분포)이기 때문에, KL divergence를 가우시안 분포 간의 KL divergence로 다시 나타낼 수 있다. \[\mathbb{E}[\frac{1}{2\sigma^2_t}||\tilde{\mu_t}(x_t, x_0)-\mu_θ(x_t, t)||^2]+C\]
Recall: \(x_t=\sqrt{\bar{\alpha_t}}x_0+\sqrt{(1-\bar{\alpha_t})}\epsilon\)
Ho et al. NeurIPS 2020 observes that: \(\tilde{\mu_t}(x_t, x_0) = \frac{1}{\sqrt{1-\beta_t}}(x_t-\frac{\beta_t}{\sqrt{1-\bar{\alpha_t}}})\epsilon\)
They propose to represent the mean of the denoising model using a noise-prediction network:
우리가 알고 싶어하는 가우시안의 평균을 다음과 같이 모델링할 수 있다.
다른 값은 모두 동일하고, \(\epsilon_θ(x_t, t)\)이라는 noise prediction network를 통해 평균을 예측할 수 있게 된다. \[\mu_θ(x_t, t) = \frac{1}{\sqrt{1-\beta_t}}(x_t-\frac{\beta_t}{\sqrt{1-\bar{\alpha_t}}})\epsilon_θ(x_t, t)\]
With this parameterization, \(L_{t-1}=\mathbb{E}_{\mathbf{x}_0 \sim q\left(\mathbf{x}_0\right), \epsilon \sim \mathcal{N}(\mathbf{0}, \mathbf{I})}[\frac{\beta_t^2}{2 \sigma_t^2\left(1-\beta_t\right)\left(1-\bar{\alpha}_t\right)}\|\epsilon-\epsilon_\theta(\underbrace{\sqrt{\bar{\alpha}_t} \mathbf{x}_0+\sqrt{1-\bar{\alpha}_t}}_{\mathbf{X}_t} \epsilon, t)\|^2]+C\)
라는 최종 loss가 나온다. \[L_{t-1}=\mathbb{E}_{\mathbf{x}_0 \sim q\left(\mathbf{x}_0\right), \epsilon \sim \mathcal{N}(\mathbf{0}, \mathbf{I})}[\underbrace{\frac{\beta_t^2}{2 \sigma_t^2\left(1-\beta_t\right)\left(1-\bar{\alpha}_t\right)}}_{\lambda_t}\left\|\epsilon-\epsilon_\theta\left(\sqrt{\bar{\alpha}_t} \mathbf{x}_0+\sqrt{1-\bar{\alpha}_t} \epsilon, t\right)\right\|^2]\]
DDPM 논문에서는 \(\lambda_t=1\) 로 설정해 주는 것이 학습이 잘 된다고 주장한다. (다르게 설정해보자는 다른 논문의 주장도 존재)
따라서 DDPM에서 사용되는 최종 loss는 다음과 같고, \[L_{\text {simple }}(\theta):=\mathbb{E}_{t, \mathbf{x}_0, \boldsymbol{\epsilon}}\left[\left\|\boldsymbol{\epsilon}-\boldsymbol{\epsilon}_\theta\left(\sqrt{\bar{\alpha}_t} \mathbf{x}_0+\sqrt{1-\bar{\alpha}_t} \boldsymbol{\epsilon}, t\right)\right\|^2\right]\]
이를 더 간단하게(\(x_t\) 치환) 표현하면 다음과 같다. \[L_{\text {simple }}=E_{t, x_0, \epsilon}\left[\left\|\epsilon-\epsilon_\theta\left(x_t, t\right)\right\|^2\right]\]
최종적으로 가우시안 모델의 평균을 예측하기 위해 스텝 사이의 노이즈를 예측하는 모델을 만들게 된다.
매 스텝마다 가우시안 노이즈를 하나 샘플링하고, 이미지에 타임 스텝 t에 맞게 노이즈를 더해준다. 네트워크는 어떤 노이즈가 더해졌는지 예측하는 구조로 학습을 진행한다.
Noise Schedule
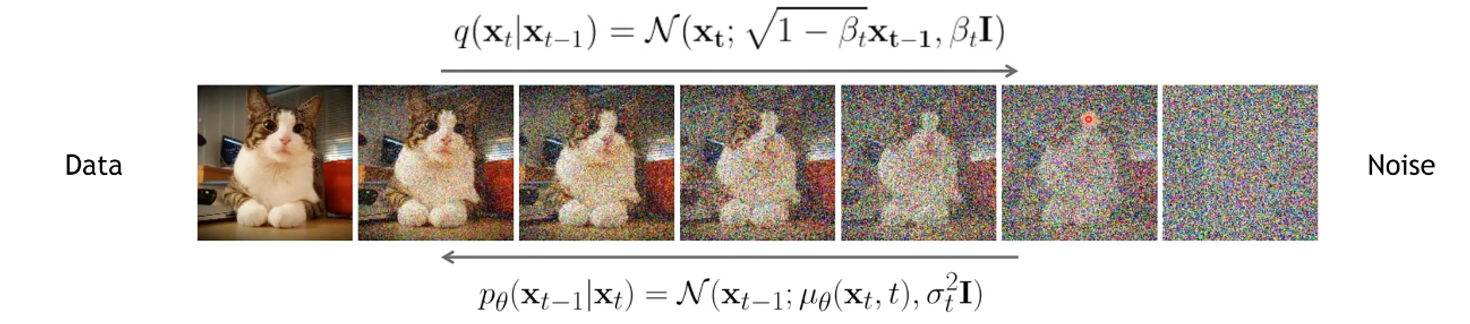
정해진 noise schedule에 따라 noise를 더해서 \(x_t\) 를 한 번에 만든다.
input: 타임스텝 t, \(x_t\)
output: 어떤 noise가 더해진건지 예측
Network Architecture
네트워크로 U-net 구조를 활용한다. 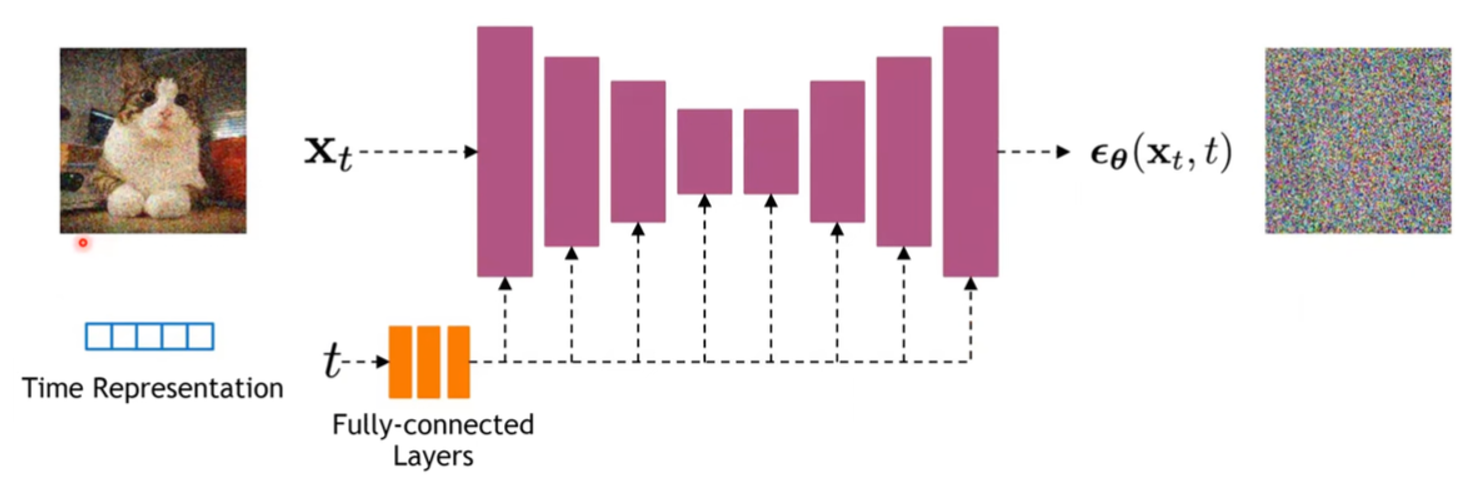
Experiment
성능 측정 지표로 IS, FID score를 사용한다. FID score는 낮을수록 높은 성능을 의미한다. 
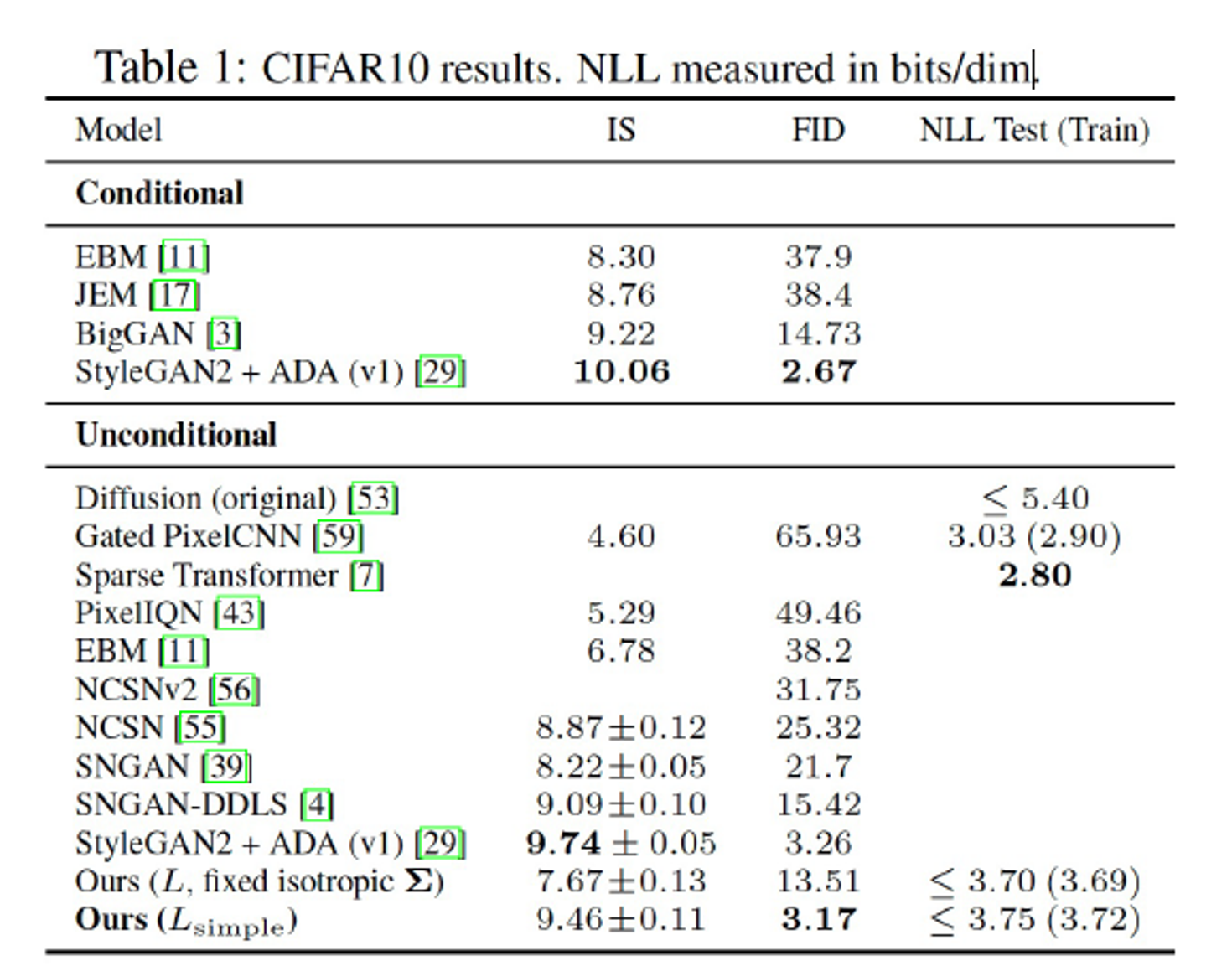 DDPM의 FID score는 3.17로서 Unconditional 생성모형 중 가장 높은 sample quality를 보인다.
DDPM의 FID score는 3.17로서 Unconditional 생성모형 중 가장 높은 sample quality를 보인다.
참고
https://hyoseok-personality.tistory.com/entry/Concept-Diffusion-Models-with-DDPM-DDIM https://learnopencv.com/denoising-diffusion-probabilistic-models/ https://www.youtube.com/watch?v=_JQSMhqXw-4 https://www.youtube.com/watch?v=uFoGaIVHfoE&t=517s
